What is Hashing in Data Structures? Concepts, Functions & Applications Explained
An important concept in computer science and programming is hashing in data structures. It is the fundamental strategy of effective data retrieval and safe data handling, with applications ranging from blockchain technology to compiler design, from caching to password verification. In the average case, hashing provides constant-time access by transforming input data (keys) into a fixed-size numerical value (hash code). This makes it vital in scenarios where performance is critical.
In problem-solving, it allows speedy frequency counting and duplicate detection in algorithm design. It helps bring down complicated operations to manageable lookups; in database indexing, it drastically improves query performance, and in security. Cryptographic hashing ensures data protection and integrity.
It is also necessary for load balancing, distributed systems, and modern applications like artificial intelligence and big data analytics.
| Key Takeaways: |
|---|
|
Introduction to Hashing in Data Structures
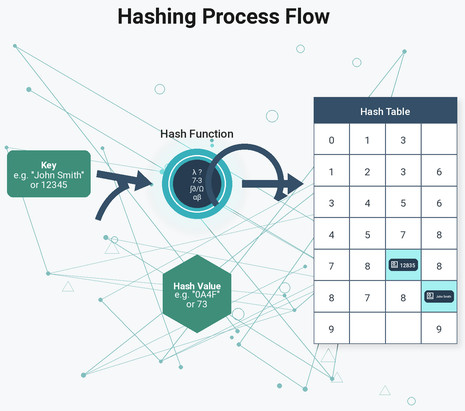
Basically, hashing in data structures is the process of converting arbitrary-sized data into fixed-sized data. In DSA, a unique function called a hash function is responsible for carrying out this mapping. This function’s output is called a hash value or hash code, which data structures use as an index in hash tables.
Efficiency is the driving force behind hashing. Hashing is one of the most efficient DSA techniques since it allows average-case constant time complexity O(1) for multiple operations, including search, insert, and delete.
What is a Hash?
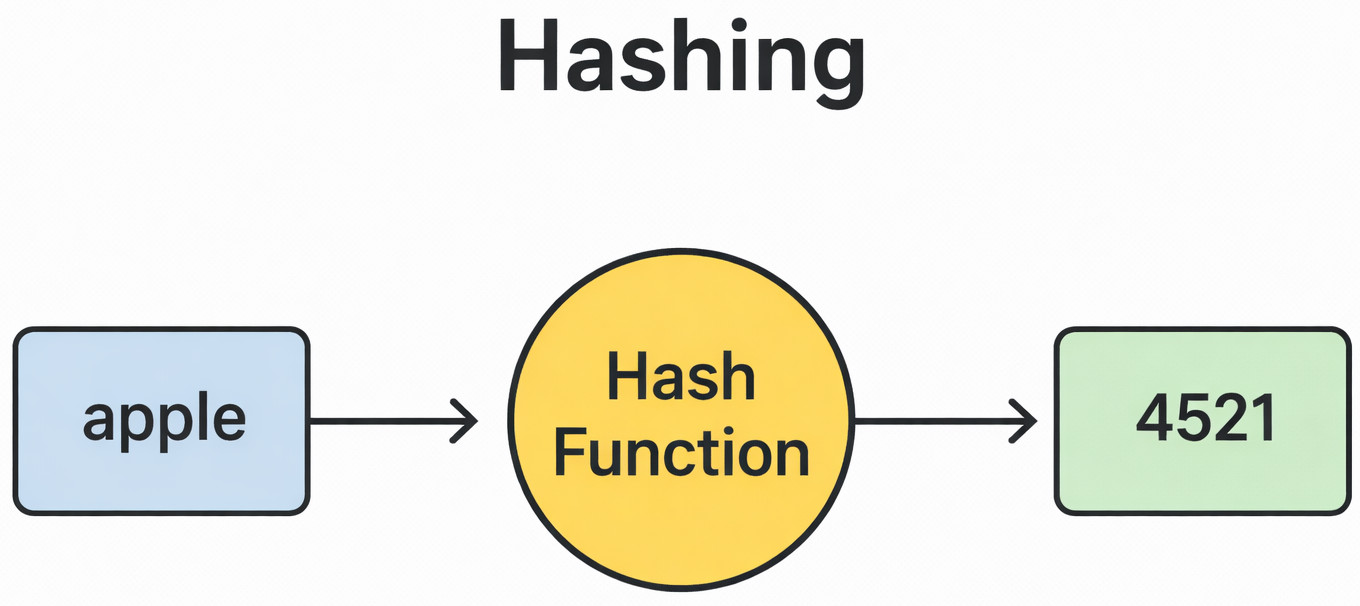
When a hash function is applied to a key, the final numerical value is referred to as a hash. A hash function may, for instance, change the key “apple” into an integer like 4521. A hash table’s index is then mapped to this integer.
As we use the hash to jump straight into the desired location rather than searching sequentially or hierarchically, hashing ensures that the data access process is extremely quick.
Hash Function in DSA
- Deterministic: The same input constantly produces the same hash value.
- Even distribution: To bring down clustering, keys should be dispersed equally throughout the hash table.
- Quick computation: To maintain O(1) performance, calculations must be completed quickly.
- Reduce collisions: This should reduce the possibility that two keys will map to the same index.
int hashFunction(int key, int tableSize) {
return key % tableSize;
}
The above simple hash function maps keys to indices inside the table size using the modulo operator.
Hash Table in Data Structures
The storage unit that stores the keys and the values that go with them in data structures is called a hash table. Usually, it is implemented as an array, with an element stored in each position (bucket). The hash function is used to compute the index for storage or retrieval.
- Memory-efficient with accurate sizing.
- Need careful handling of collisions.
- Provides faster average performance for insert, delete, and search operations.
Hash tables are frequently used in DSA code examples to implement dictionaries, sets, and maps.
Types of Hashing Techniques
Different methods can be utilized to implement hashing, and these are necessary in DSA when building efficient algorithms. Let’s explore the different hashing methods:
Division Method
The index is built by dividing the key by the size of the table.
Simple but sensitive to table size,
Index = key % tableSize;
It is the most efficient with prime table sizes.
Multiplication Method
After multiplying a key by a constant (0 <A <1), the fractional part is taken and multiplied by the size of the table.
Mid-Square Method
The middle digits of the result are leveraged as the index after the key has been squared.
Folding Technique
The index is created by adding or XORing the equal portions of the key.
Each method has trade-offs, and the choice depends on the nature of the input data.
Collision Handling in Hashing
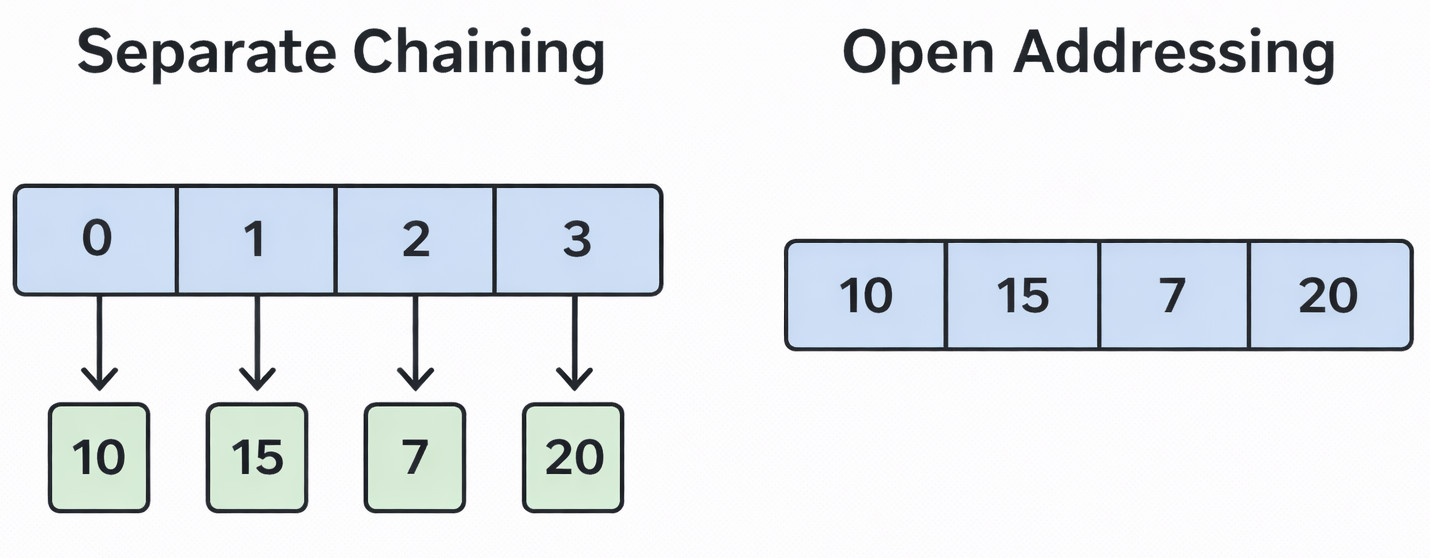
In practice, collisions are unavoidable even with well-designed hash functions. When two unique keys map to the same hash table index, a collision occurs.
Techniques for Collision Handling in Hashing:
Separate Chaining
- A linked list of entries is defined by each slot in the table.
- Two keys are stored in the same bucket as a list if they hash to the same index.
Open Addressing
- The hash table itself contains all of the entries.
- Methods include:
- Linear Probing: Search for the next open slot in a sequential manner.
- Quadratic Probing: Using quadratic steps to solve collisions.
- Double Hashing: To identify the next slot, use a second hash function.
Rehashing
- A new, larger table is made, and every element is rehashed when the load factor (number of elements/ table size) crosses a threshold.
Efficient collision handling in hashing is needed for maintaining O(1) performance in practice.
Common Hash Functions in Practice
While theory provides a range of methods, some hash functions are more commonly used in practical development due to their effectiveness and resilience.
Division-Based Hash Functions
These functions are efficient for small datasets and are often used in simple systems and instructional examples.
Polynomial Rolling Hash
Often used in Rabin-Karp and other string matching algorithms. It balances performance and collision avoidance.
Cryptographic Hash Functions
Functions such as MD5, SHA-1, and SHA-256 are made to be both secure and distributed. Digital signatures, blockchain, and authentication are all dependent on them.
Developers can establish whether they need speed, security, or a combination of the two by understanding these commonly used hash functions.
Load Factor and Its Importance
- A high load factor emphasizes efficient memory use but also raises the possibility of collisions.
- A low load factor indicates reduced collisions but may lead to memory waste.
The majority of implementations, like Java’s HashMap, automatically resize the table when the load factor increases over a certain point, usually 0.75. To maximize speed and memory usage, developers need to be cognizant of this trade-off.
Hashing versus Other Data Structures
- Arrays: Offer O(1) access, but only for arbitrary keys, not for numeric indices.
- Linked lists: O(n) searches are required, but they are excellent for dynamic insertion.
- Binary Search Trees (BSTs): In most scenarios, they are slower than hash tables but provide O(log n) operations.
- Tries: Memory-intensive but efficient for string-related issues.
While it sacrifices ordering, hashing provides speed and flexibility, which builds a balance.
Hashing in Competitive Programming
Hashing is vital in coding contests. Hash tables are often used to solve problems with frequency counting, substring matching, and duplicate detection. Rolling hash functions are specifically well-liked for efficiently resolving string problems.
In competitive settings, advanced programmers are often differentiated from novices by their understanding of collision handling in hashing and their capacity to build unique hash functions.
Applications of Hashing in Programming
- Data Retrieval: Hash tables, which are ideal for dictionaries and symbol tables in compilers, enable fast lookups in constant time.
- Databases: Hashing is mandatory for indexing in databases in order to execute queries quickly.
- Cryptography: Hashing algorithms (SHA, MD5) ensure message integrity and safe password storage.
- Caching: Hashing is utilized by file systems, databases, and web browsers to swiftly validate the contents of their caches.
- Distributed Systems: In load-balancing systems, hashing delegates the workload equally among servers.
- Compiler Design: Hash tables are used in compilers to implement symbol tables so that identifiers can be swiftly found.
- Security and Blockchain: Hashing is a key component of blockchain for immutability and transaction verification.
Advantages and Disadvantages of Hashing
Understanding when to use hashing is made easier by being cognizant of its benefits and drawbacks:
Advantages:
- Efficiency: Average constant time O(1) for search, insert, and delete.
- Flexibility: Able to work with a range of data types, such as numbers and strings.
- Scalability: Performance can be maintained even as data volume grows with relevant rehashing.
- Versatility: Applied to caches, compilers, databases, and cryptography systems.
Disadvantages:
- Collisions: These are inevitable and can degrade performance if not managed correctly.
- Memory Overhead: The load factor and table size must be properly balanced.
- No Ordering: Unlike trees, hash tables do not keep sorted data.
- Rehashing Cost: Resizing needs rehashing of every component, which is expensive.
Despite the restrictions, the benefits often outweigh the drawbacks, especially for applications needing high-speed lookups.
Real-World Uses of Hashing
- Password Security: For security purposes, websites store hashed passwords rather than plain text.
- Checksum and Data Integrity: Hashing is used in file transfers to guarantee that the data has not been corrupted.
- Search Engines: Hashing accelerates web page indexing and retrieval.
- Content-Based Addressing: Hashing is used by systems such as Git to manage versions and monitor changes.
- Spam Filtering: Email systems use hashing to quickly detect patterns of known spam.
Hashing in DSA: A Developer’s Perspective
- For O(1) lookups in Python, programmers use
dict. - In Java,
HashMapis the preferred data structure for key-value storage. - In C++,
unordered_mapis often used in DSA code.
Understanding hashing in DSA also enables developers to get ready for interviews, where topics such as load factor management, collision handling, and real-world applications are often discussed. A dev will stand out if they can handle different hashing techniques, write their own hash functions, and include collision handling in hashing.
Challenges in Implementing Hashing
- Creating Effective Hash Functions: Clustering results from poorly selected functions.
- Handling Collisions: The use case determines whether to use open addressing or chaining.
- Memory Overhead: Finding a balance between performance and load factor.
- Resizing Costs: Rehashing can be computationally expensive.
Developers are better able to handle large-scale data systems when they are conscious of hurdles.
Future of Hashing in Modern Computing
- Cloud infrastructure and distributed systems both make extensive use of consistent hashing.
- In artificial intelligence, hashing is used to detect the approximate nearest neighbor of high-dimensional data.
- Quantum computing might call for more advanced, secure hashing algorithms.
- Hashing is now an enabler for cutting-edge technologies rather than just a tool for small datasets.
Conclusion
In summary, hashing in data structures is a method that utilizes hash tables and hash functions in DSA to aid in quick data access. Developers can achieve near-cin onstant time performance for critical operations by using appropriate hashing techniques and efficient collision handling.
Its influence goes far beyond theory; it works as the foundation for everything from blockchain to compilers. The uses of hashing in programming are too vast and significant to ignore, despite its disadvantages, which include collisions and rehashing expenses.
Hashing is a basic component of modern computing, with applications ranging from database indexing to practical applications in cloud and security systems. It is not only mandatory, but also vital for any developer learning DSA to have a thorough understanding of hashing.
Additional Resources
- Why Learning Data Structures and Algorithms (DSA) is Essential for Developers
- Searching vs Sorting Algorithms: Key Differences, Types & Applications in DSA
- Arrays in Data Structures: A Complete Guide with Examples & Applications
- Data Structures and Algorithm Complexity: Complete Guide
- Tree in Data Structures: A Complete Guide with Types, Traversals & Applications
|
|