Context Engineering for AI Agents: A Step-by-Step Guide
Artificial intelligence (AI) is no longer about simple chatbots; it has evolved into sophisticated autonomous agents capable of reasoning, planning, and executing multi-step tasks. Earlier, AI was driven by prompt engineering. However, nowadays, a new term has come to prominence: Context Engineering.
| Key Takeaways: |
|---|
|
This article provides a comprehensive, step-by-step guide to context engineering for AI agents, covering its principles, components, strategies, and real-world implementation techniques.
What is Context Engineering?
Context engineering is the art and science of curating the right information and selecting the right reference materials for an AI model at the right time.
While prompt engineering focuses on crafting a single instruction, context engineering focuses on designing the entire environment in which an AI agent operates.

- What the agent sees
- How it’s structured
- When it’s injected
Context keeps even the 75th step as clean and clear as the first.
Analogy
As an analogy, you can take an example of an exam. Prompt engineering involves writing exam questions.
Context engineering, on the other hand, chooses the reference materials (notes, textbooks, etc.) you bring into the examination hall.
As stated above, a prompt is for an individual question in an exam, while context is for an entire exam environment.
Context engineering acts like a memory management system for AI agents. As humans, our cognitive ability relies on various types of memory, such as working, long-term, and episodic. AI agents also need sophisticated context management to operate effectively in complex, multi-turn scenarios by applying the right context at the right time.
- Dynamic: The context evolves with every interaction.
- Selective: Only relevant information is included in the context.
- Structured: Information is organized to ensure clarity and efficiency.
- Iterative: The context is continuously refined across steps, taking into account the output of the previous step.
Context engineering provides LLMs with specific references and situational data, enabling them to generate more reliable, accurate output. This is because, with correct context, LLMs don’t guess but know the actual business, helping them generate highly relevant, grounded, and factual responses.
Context engineering, with its ability to strategically manage information flow to and from AI agents, is becoming increasingly vital as enterprise AI agents scale. It helps optimize performance, accuracy, and cost.
Why Does Context Engineering Matter?
The practical success of LLMs is critically dependent on the external information and tools provided to them at the moment of inference.
- Static knowledge: LLMs are not aware of current events, as their understanding of the world freezes at the last training date.
- Limited Context Window: They have no access to the documents, metrics, or logs that contain the most valuable context. So they do not have live, current information. LLMs can only process a finite amount of information at once, known as the context window.
- Hallucinations and Lack of Grounding: LLMs predict the next most probable token in a sequence. It lacks factual verification and may generate hallucinated output.
- Contextual Drift and Lack of Memory: Agents lack persistent context or memory and struggle with multistep tasks. They cannot recall previous decisions and thus re-infer information. This results in inconsistent behavior and ultimately failure.
- Context Rot: As more information is added, LLMs may lose focus and degrade in performance, a phenomenon known as context rot. They produce incorrect outputs when trained on too much irrelevant data.
- Real-World Complexity: Production AI agents are expected to handle long conversations, utilize multiple tools, access external data sources, and maintain memory over time. If there is no proper context, these systems may become unreliable.
- Context engineering architects the entire information ecosystem surrounding the AI model.
- It curates its context window at any given moment and decides what information from messages, tool outputs, or its own internal thoughts should make it into the agent’s “working memory,” which is limited.
- It helps design the information architecture that powers intelligent agents, just as developers architect software systems by designing databases, APIs, and data pipelines to optimize workflows.
- Context engineers manage which information occupies the LLM’s limited “working memory” (the context window) and which is retrieved from “persistent memory” (e.g., a vector database).
- Without context engineering, even the most capable LLM cannot compensate for poorly structured, incomplete, or irrelevant context.
Components of Context in AI Agents
First and foremost, you have to understand what constitutes a context before you engineer it effectively.
AI agents use context as the set of inputs that can be seen and used to reason. You can visualize context as the kit you organize for a task at work: clear instructions, jot down the specific questions, take recent notes, list trusted facts, use relevant tools, and know when to move to the next step. If any piece is missing or noisy, you get different answers, and reviews take longer. In the same way, context in AI agents is also a kit that has various components that work together to produce output.
Here are the different components of context in AI agents:
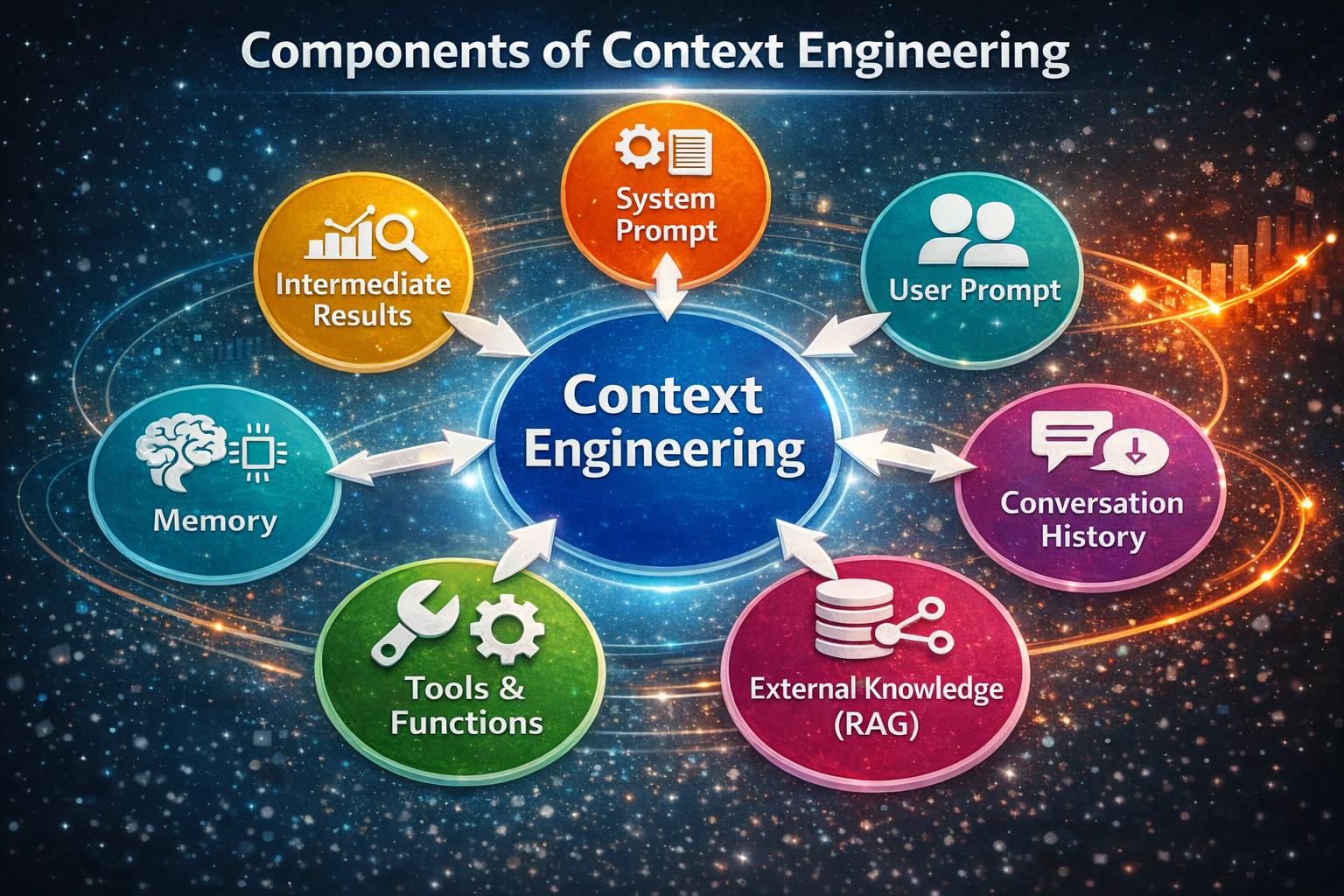
System Prompt/Instructions
System prompts determine the AI agent’s behavior, constraints/safety rules, and objectives. Using a system prompt, the model understands how to act. In a way, the system prompt establishes the AI agent’s foundational context involving its capabilities, identity, constraints, and behavioral guidelines.
The system prompt is relatively stable and does not change with each instruction. It, in a way, acts as a persistent rulebook and “personality”. A system prompt is said to be effective when it balances three competing demands, namely, specificity (prompt is clear enough to prevent ambiguous behavior), flexibility (it is general enough to handle diverse scenarios), and conciseness (prompt is brief enough to preserve context window space).
User Prompt
A user prompt is the query or instruction that the user inputs to seek a response. It captures the specific question and any constraints, such as customer segment, region, or time window.
The user prompt defines the immediate task context and is not static like a system prompt. It changes with each interaction and is the component that has highest attention in most LLM architectures. User prompts often override conflicting information in the context with this positional bias.
In context engineering, user prompts are more than simple questions; they include explicit context hints, such as timestamps, user preferences, and session state. These hints guide retrieval and tool selection without inflating the system prompt.
Conversation History
Previous interactions that provide continuity to AI models is the conversation history. It contains the record of what has been said, done, or learned within the current interaction. Conversation history is synonymous to “working memory” of the agent and is a short-term memory. To enable conversational continuity, the agent references previous exchanges from history. Thus, users need not repeat context. The drawback, however, is that conversation history grows linearly with interaction length, quickly consuming the context window.
External Knowledge(RAG)
RAG or external knowledge is a component of context engineering for the retrieved documents, databases, or APIs. An AI agent retrieves external data “just in time” from a knowledge base. AI models can answer questions using this information it was not trained on in the first place. The RAG component ensures the responses it generates are both accurate and current.
Tools and Functions
Using tools in an AI agent extends an agent’s capabilities beyond text generation as it enables its interaction with external systems. External actions such as executing code, calling APIs, querying databases, or manipulating files can be achieved using these tools and functions.
Tool context includes a description (name, purpose, parameters, usage examples) that consumes context window space. However, as tool libraries grow, the tool context overhead becomes significant. For instance, a 100-tool agent might spend 30%–40% of its context window just describing available capabilities before the user’s actual task begins.
Memory
In context engineering, there is a short-term memory and a long-term memory. Short-term memory stores information from past interactions. AI agents use long-term memory to retain information across multiple sessions or conversations. AI can recall user preferences, past interactions, and learned facts for future reference using long-term memory.
Intermediate Results
These are the responses from previous steps in multi-step workflows. Tool results and prior answers are normalized into concise facts that can be consumed by the next step. This is a structured output that AI uses to format in a specific way, such as JSON, XML, or a table. AI responses are consistent and easily used by other programs or systems when outputs are structured.
Core Principles of Context Engineering
Context engineering is used to maximize accuracy, relevancy, and efficiency in LLMs by strategic curation, structuring, and management of information. It is more than prompting and creates modular, high-signal, and dynamic inputs, utilizing RAG and memory management to improve performance and reduce hallucinations.
- High-signal Context (Less is More): With focus on quality instead of quantity, only the most relevant, high-signal information is provided that reduces noise, prevents hallucinations, and speeds up inference.
- Modular Context Schema: Information is organized into structured, reusable components (e.g., roles, objectives, constraints) instead of using a single, unstructured blob.
- Dynamic Information Management: The context window is actively managed using techniques such as summarization of past conversations, RAG for external data, and context windowing (retaining only recent information).
- Explicit Constraints and Instructions: What the model should do and should not do is clearly defined in addition to specific formatting rules and behaviors to eliminate ambiguity.
- Context Isolation: To ensure that each part of the system only sees the information relevant to specific roles, the context for specialized agents or sub-tasks is clearly separated.
- Temporal Awareness: As context changes over time, stale information is either updated or purged to ensure accuracy.
Step-by-Step Guide to Designing Context in Context Engineering
Here is a sequence of steps to design context in AI agents:

Step 1: Define the Task and Objectives
Begin by clearly defining objectives and tasks by analyzing what the agent needs to accomplish, what the expected results are, and various constraints and rules you want to impose.
This step makes sure that context serves a specific purpose.
Step 2: Identify Required Context Sources
This step is to create a blueprint for context construction. It identifies the context sources needed, such as static instructions (system prompt), dynamic inputs (user queries), external data (APIs, databases), and memory (past interactions).
Step 3: Design the Context Structure
Structured context is necessary as it improves model comprehension and reduces ambiguity. At this step, context structure is designed by organizing it into logical sections consisting of role and instructions, task-specific data, retrieved knowledge, and interaction history.
Step 4: Implement Context Selection
Not all available information should be included in the context. Modern systems make use of retrieval mechanisms like vector databases to extract relevant information. Selection strategies such as semantic relevance (similarity search), recency weighting, and task-specific filtering.
Step 5: Apply Context Compression
Context has to fit within the context window. For this purpose, context compression techniques such as summarizing older conversations (aka sliding window with summarization), compressing documents, or removing irrelevant/redundant data are used.
Step 6: Manage Memory
Memory is a critical component of context engineering and has to be managed efficiently for effective context engineering.
- Short-term memory: Current session context
- Long-term memory: Persistent knowledge across sessions
Effective memory systems can store relevant information, retrieve it when needed, and avoid unnecessary clutter.
Step 7: Integrate Tools and External Data
This is the step for external data and tools integration. AI agents often rely on tools such as APIs, databases, calculators, and search engines. Context engineering ensures that only relevant tools are included in the AI agent, the tool descriptions are concise, and outputs are properly integrated.
Step 8: Handle Multi-Step Workflows
Complex tasks have multi-step workflows. In this multi-step workflow, each step generates a new context, and intermediate results generated must also be managed.
Strategies for handling multi-step workflows include passing only essential outputs, summarizing intermediate steps, and isolating context per task phase.
Step 9: Prevent Context Failures
- Context Poisoning: Irrelevant or malicious data present in the context corrupts the context.
- Context Clash: There is conflicting information that leads to confusion.
- Context Drift: The AI agent loses track of the original goal.
To prevent context failures, mitigation strategies such as validation and filtering, clear instruction hierarchy, and context isolation techniques are employed.
Step 10: Monitor and Iterate
Context engineering is a continuous process, and to get greater benefits, you should continuously analyze agent performance, identify failure patterns, and refine context strategies.
Key Techniques in Context Engineering
Many frameworks categorize context engineering strategies into four main techniques:
Write
Writing technique in context engineering involves storing information outside the immediate context window for future access. Writing techniques create a persistent layer (long-term memory) that can be accessed across sessions and tasks. Define clear instructions and constraints.
- Long-term Memory: This is the memory consisting of user preferences, learned behaviors, and historical interactions, and persists across sessions.
- Short-term Memory: This type of memory is available within a session and includes conversation history, temporary variables, and workflow state.
- State Objects: These are the objects responsible for runtime state management, such as current task progress, temporary calculations, and session variables.
Read
This technique is used for strategic information retrieval. Read context techniques pull relevant information strategically into the agent’s working context window. Sophisticated retrieval mechanisms such as relevance scoring are used for this purpose.
- Tools: External APIs, databases, file systems
- Knowledge Bases: Documentation, vector databases, structured data
- Memory Systems: Previously stored context from write operations
- Semantic Search: Vector embeddings are used to find contextually relevant information
- Recency Weighting: Recent interactions and updates are prioritized
- Task-Specific Filtering: Only the context relevant to the current objective is retrieved
- Progressive Loading: Starting with essential context, additional details are loaded as needed
Compress
To fit the information in the current context window, context compression techniques are used. The compression technique involves intelligent summarization of information that often contains redundancy, irrelevant details, or excessive verbosity. Compression reduces the size of the context while maintaining essential information and reducing token usage.
- Hierarchical Summarization: Layered summaries consisting of detailed, medium, and high-level layers (detailed -> medium -> high-level) are created for information.
- Entity Extraction: This technique focuses on key entities, relationships, and facts.
- Intent Preservation: Compression of context is performed while ensuring that the original intent and meaning of the context is preserved.
- Template-based Compression: Structured formats are used to standardize compressed output.
Isolate
In the isolation technique, different types of context are strategically separated to avoid interference and enable specialized processing. The isolation technique is especially crucial for complex applications with multiple concerns.
- Multi-agent Architecture: In this technique, different agents handle different aspects of the problem without any interference.
- Sandbox Environments: This technique isolates execution contexts for code, experiments, or sensitive operations.
- State Partitioning: State objects for various functional domains are separated in state partitioning technique.
The Types of Context
Understanding the different types of context that AI agents need is essential for effective context engineering. Here are the six types of context often used:

1. Instructions Context (System Prompt)
The instructions context defines the persona, goals, constraints, and behavioral rules that the agent should adopt. This context is also called the system prompt.
For example, the prompt "Act as a data analyst" defines the persona, role, and goals of this role.
2. Examples Context (Few-Shot Prompting)
Example context, aka few-shot prompting, demonstrates desired behavior, reasoning steps, or output formats to guide decision-making.
For example, the prompt "What should a good output look like?" demonstrates the example’s context.
3. Knowledge Context (Internal/External)
The knowledge context involves domain-specific data, documents, or databases accessed to enhance accuracy that is often retrieved through Retrieval-Augmented Generation (RAG).
4. Memory Context (Short-term & Long-term)
This type of context stores recent interactions (short-term) or user preferences/history (long-term) for continuity across sessions.
5. Tools Context (Capabilities)
The tools context defines API descriptions or functions that allow the agent to perform actions beyond generating text (e.g., browsing, calculation).
6. Guardrails Context
Guardrails context determines safety constraints that validate inputs (clean, safe) and actions (safe, approved operations) to ensure compliance.
Real-World Applications of Context Engineering
Context engineering is essential when you start building AI applications that need to work with complex, interconnected information. For example, a customer support bot is expected to maintain a friendly conversation tone while accessing previous support tickets, checking account status, and referencing product documentation.
In such a case, traditional prompting breaks down as it lacks context. Here are a few such real-world applications where context engineering becomes necessary:
Customer Support Agents
AI agents, such as customer support agents, make context dynamic and responsive. They use external tools during conversations instead of just retrieving static documents. An agent starts a conversation, realizes the need for current stock data, calls a financial API, and uses this fresh information to continue the conversation.
The AI also decides which tool will be best to solve the current problem. Multi-agent systems are also possible due to the decreasing cost of LLM tokens. You can have specialized agents that handle various aspects of a problem and use protocols like A2A or MCP to exchange information.
Coding Assistants
AI coding assistants, such as Cursor or Windsurf, are the most advanced applications of context engineering. They work with highly structured, interconnected information, combining both RAG and agent principles.
Coding assistants need to understand individual files as well as entire project architectures, dependencies between modules, and coding patterns across the codebase.
For example, when you ask a coding assistant to refactor a function, it needs the function context, like where the function is used, what data types it expects, and how changes might affect other parts.
Hence, context engineering becomes critical here because code can have relationships that span multiple files and even multiple repositories. A good coding assistant has to maintain context about your project structure, recent changes made, individual coding style, and the frameworks used.
Coding assistants build up context about your specific codebase to provide relevant suggestions based on patterns. Hence, these coding assistants work better the longer you use them in a project.
Read: Code Generation: From Traditional Tools to AI Assistants.
RAG Systems
RAG was one of the first techniques that let you introduce LLMs to data that wasn’t part of their original training data. Therefore, you can say that context engineering arguably started with RAG systems.
RAG systems organize and present information more effectively using advanced context engineering techniques. Information documents are broken down into meaningful pieces ranked by relevance, and fitted with the most useful details within the token limits.
Before RAG systems, you had to retrain or fine-tune the entire model if you wanted an AI to answer questions about your company’s internal documents. With RAG, this is no longer required. They just search through your documents, find relevant chunks of data, and include them in the context window.
This enables LLMs to analyze multiple documents and sources to answer complex questions that would normally require a human to read through hundreds of pages.
Challenges in Context Engineering
- Dumping Everything into Context: Teams throw in documents, chat history, and all other raw stuff in the tools randomly and hope that the model will somehow make sense of this information. However, the models get overwhelmed and miss crucial details.
- No Explicit Task Start: The AI agent infers progress from conversation history and repeats steps, misses what is already fetched, or jumps ahead.
- Storing Guesses as Memory: A wrong guess is written into memory and keeps resurfacing, causing issues like hallucinations as the agent becomes confidently wrong.
- Tool Overload and Overlapping Tools: The AI agent calls the wrong tool, calls multiple tools, or loops, as multiple tools can solve the same problem.
- Raw Tool Outputs Polluting the Context: When the context window is flooded with large JSON, logs, or tables, the agent focuses on noise and loses the thread.
Future of Context Engineering
- Context-aware architectures
- Model Context Protocols (MCP)
- Reinforcement learning for context optimization
Conclusion
Context engineering is the discipline that forms the backbone of modern AI agent design. While prompt engineering is still relevant and introduces the world to interacting with AI, context engineering enables AI to operate reliably in complex, real-world scenarios.
By carefully selecting, structuring, and managing information, developers can transform AI agents from fragile prototypes into robust systems capable of handling multi-step tasks and long-term interactions.
Frequently Asked Questions (FAQs)
- Why is context engineering important for AI agents?
Context ensures you receive accurate, consistent, and relevant outputs from AI agents by controlling what information they receive and how it is structured.
- What is the context window limitation?
It refers to the maximum amount of information (tokens) an AI model can process at once. Exceeding this limit can lead to loss of important information.
- How can developers manage a large context effectively?
By using techniques like summarization, retrieval-based context selection, filtering irrelevant data, and maintaining structured memory systems.
- What is context rot in AI systems?
Context rot occurs when too much or irrelevant information is included, causing the model’s performance to degrade or produce inaccurate responses.
- What role does memory play in context engineering?
Memory allows AI agents to retain important information across interactions, enabling continuity, personalization, and better decision-making.
- Can context engineering improve AI accuracy?
Yes, well-designed context significantly improves accuracy by ensuring the model has access to relevant and structured information.
|
|