Serverless 2.0: What the Next Wave of Cloud Abstraction Means for Developers
Serverless technology has always been simple: Write code, not infrastructure. The first wave of serverless (Serverless 1.0) primarily focused on individual functions triggered by events. The second wave of serverless technology, Serverless 2.0, represents the next evolution in cloud computing.
| Key Takeaways: |
|---|
|
From Serverless 1.0 to 2.0: What’s New?
Serverless 1.0 supported a Function-as-a-Service (FaaS) model that focused on individual functions triggered by events. Serverless 2.0 represents an evolution beyond Serverless 1.0, focusing on enhanced capabilities like state management, enterprise integration, and advanced messaging, making it suitable for a broader range of applications. This includes features like persistent state, streaming APIs, and AI-native infrastructure.
Here are the main highlights of both serverless versions, 1.0 and 2.0.
- Functions-as-a-Service (FaaS) with ephemeral containers and event triggers.
- “Stateless by design” compute; state pushed to external stores.
- API gateways and message buses stick everything together.
- Pay-per-invoke economics that resulted in bursty, spiky traffic.
- Limitations in handling complex workflows.
- It has durable, long-lived workflows built on serverless runtimes (sagas, retries, compensations, exactly-once semantics).
- It supports serverless databases and data “close to compute,” including strongly consistent global tables and low-latency edge caches.
- Its edge-native runtimes with near-zero cold starts, KV/object stores, queues, and CRON, deployed to dozens or hundreds of PoPs.
- AI-native primitives (embedding stores, model gateways, function calling) integrated as first-class services, not bolt-ons.
- Platformized developer experience offers opinionated scaffolding, IaC baked in, unified logs/metrics/traces, and runtime policies by default.
- Fine-grained security envelopes (least privilege by default, managed secrets, IAM per-function, runtime attestation).
In short, serverless 2.0 aims to make serverless computing more robust, versatile, and enterprise-ready by addressing the limitations of the initial FaaS model. It also seeks to incorporate features that support a wider range of applications and workloads.
Read more about Serverless Computing in Software Engineering.
Core Characteristics of Serverless 2.0
Serverless 2.0 focuses on enhanced capabilities and maturity, particularly in integration, state handling, and enterprise-level features. Key characteristics of serverless 2.0 include event-driven execution, automatic scaling, pay-as-you-go pricing, and server management abstraction. There is also an emphasis on improved security, performance optimization, and reduced operational overhead. Here is a broader categorization of serverless 2.0’s core characteristics and how they impact developers:
1. Durable Compute, Not Just Ephemeral Functions
Serverless workflows (state machines, durable tasks) turn multi-step operations into first-class code. Declarative constructs like retries, backoff, timeouts, idempotency, and compensation are used. The platform tracks progress and state safety across failures instead of developers hand-rolling orchestration in cron jobs and queues.
Developer Impact: They think in process lifecycle rather than single invocations, as concurrency and resilience move from “ad hoc patterns” into your DSL or SDK.
2. State as a Service (Without Footguns)
The data plane matures as serverless SQL/NoSQL with automatic scaling, multi-region replication, global tables, and row-level TTL change streams. Edge data layers (KV, durable objects, global caches) reduce tail latency. The goal is to know where the user is.
Developer Impact: Developers will choose between “global strong consistency,” “region-pinned consistency,” or “eventual with CRDTs.” Patterns like command query responsibility segregation (CQRS) and materialized views become the norm for performance.
3. Edge-First Delivery
In serverless 2.0, edge runtimes aren’t just for CDN rules anymore. They run handlers, scheduled tasks, WebSockets, and AI inference warm caches. App code is deployed to dozens of regions by default, often with no container boilerplate.
Developer Impact: The latency budget is improved. However, data locality becomes a design concern. Resort to partitioning the state or selectively routing users to “home regions.”
4. AI-Native Integrations
The serverless 2.0 platform offers managed gateways to foundation models, streaming responses, function calling, and vector indexes. It handles access control, metering, and prompt redaction upstream.
Developer Impact: They can focus on orchestration, safety rails, and evaluation, and less on managing model endpoints or GPUs.
5. Opinionated Security and Compliance
Serverless 2.0 offers Identity Access Management (IAM) policy generation, least-privilege defaults, secrets rotation, VPC-less private links, software bill of materials (SBOMs), and policy-as-code.
Developer Impact: Security posture is improved. Developers must only internalize guardrails (e.g., why a function can’t reach a resource by default).
How Architecture Changes in Serverless 2.0
Serverless 2.0 represents the evolution of serverless computing. It introduces shifts in architectural patterns and considerations compared to earlier serverless implementations.
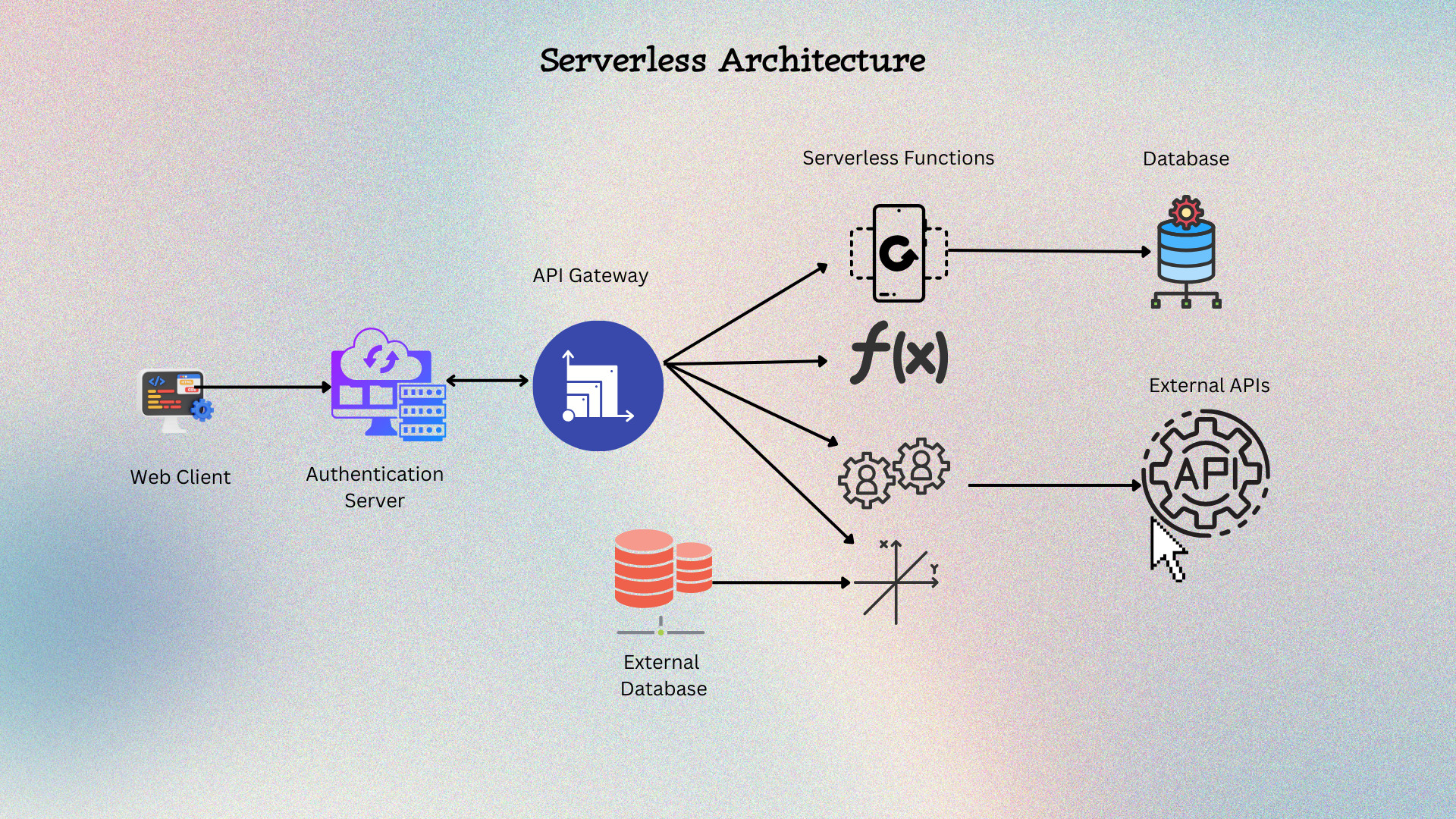
Key changes in architecture include:
Event-driven Backbones With Built-In Orchestration
Workflows like order placement, user signup, billing cycle, and post-purchase emails are built as defined sagas instead of a soup of lambdas and topics. The system persists state transitions automatically.
It has built-in orchestrators with explicit steps, retries, and compensations, and its observability renders a timeline of the business process.
State Management: Beyond “Put Everything in S3 and Hope”
- Hot path stores such as low-latency KV or memory objects at the edge,
- System of record (serverless SQL/NoSQL, region-pinned or global),
- Analytical tier (serverless warehousing/lakes with auto-suspend/auto-resume),
- Streaming change data capture (CDC) to keep views materialized.
Concurrency and Idempotency as First-Class Concerns
Serverless gives developers “infinite” concurrency. They offer automatic idempotency keys, exactly-once semantics for workflows, and transactional outbox patterns, reducing duplicate side effects.
Networking, Private Access, and Zero-Trust
Serverless 2.0 platform offers simplified patterns with private endpoints without VPC tax, identity-aware routing, and service-to-service auth based on workload identities (OIDC, SPIFFE). For developers, it means fewer NAT gateways and more policy-as-code.
Edge & Distributed Application Patterns
- Static + Edge Dynamic Fusion: In this, HTML is served at the edge and enriched with user-region session data from a KV. It fetches critical product data from a close-read replica and returns to its origin only for writing.
- Geo-Sharded Tenancy: Each customer is assigned a “home region” for writes, and read views are replicated globally.
- Edge Compute for Realtime Collaboration: Durable objects or region-pinned rooms coordinate WebSocket sessions, and snapshots persist to global storage.
- Edge AI Inference Gateways: Cache model responses and embeddings near users are used to ship updated safety policies without redeploying app code.
There is still a trade-off; while edge scales read paths magically, developers must adjust write amplification and cross-region chatter.
How Costs Behave in Serverless 2.0
- Granular compute meters measure beyond GBs. They measure CPUs, vCPUs, requests-per-second bands, and provisioned concurrency-like warm pools.
- Data egress and cross-region replication matter more as you go global.
- Storage classes (hot KV vs. durable objects vs. standard DB vs. cold) drastically change a feature’s unit cost.
- AI costs change with context length, tool call fan-out, and evaluation workflows.
- Keep budgets and alerts on per-service SKUs (compute, DB, egress, AI).
- Use usage caps per tenant and backpressure strategies.
- Build cost-as-code dashboards that map user flows to unit economics.
- Prefer TTL policies on caches and short-lived data to avoid silent bloat.
Security & Compliance in Serverless 2.0
- Serverless 2.0 offers the least privilege by default for every function and workflow step, and it does not overscope wildcards.
- It uses rotation for managed secrets, avoiding baking credentials into code or environment variables.
- It provides runtime attestation and SBOMs for supply chain clarity.
- Serverless 2.0 uses data residency and sovereignty tooling to pin certain tenants to regions.
- PII tokenization and field-level encryption are used where needed.
- Audit trails are used as append-only logs.
Developer’s Take: It Finally Feels Like an App Platform
- It offers CLIs that generate an app with routing, data, auth, and tests that are prewired.
- A unified local dev is running a near-real runtime plus mocks for cloud services.
- It provides hot reload and time-travel debugging for workflows.
- A single deployment target that fans out to the edge, regions, and data migrations.
- It favors declarative stacks combining workflows, permissions, and data schemas.
- Serverless 2.0 uses preview environments on every PR to validate latency, quotas, and cost deltas.
Migration Strategies to Serverless 2.0
Migrating to Serverless 2.0 should consider the existing application’s specific needs and complexities. A common strategy is to start with a “lift and shift” or “rehosting” strategy, moving the application to a serverless environment with minimal code changes, then gradually refactoring and optimizing for serverless benefits. Refer to Cloud Migration for more information on migration strategies.
Alternatively, a more aggressive approach breaks down the application into smaller, independent functions (microservices) and uses serverless features like AWS Lambda and API Gateway.
- Start with a Single Journey: Choose one cross-service flow, such as onboarding, and rewrite it with clear SLAs and monitoring into a durable workflow.
- Carve Out Read-Heavy Features to the Edge: Move product details pages, search suggestions, and feature flags to edge caches/KV to cut p95 latency.
- Introduce a Serverless DB for New Modules: New bounded contexts use the serverless store; backfill asynchronously via CDC. So avoid forklift migrations.
- Wrap Legacy Services: Use queue/event bridges for integration. Until paths are retired, let the new workflow orchestrate calls to the old monolith.
- Build a Platform Template: Include decisions (like auth, logging, cost controls, policies) in a starter repo for new services.
- Recreating the monolith as a spaghetti of functions without clear ownership.
- Over-duplicating data globally “just in case.”
- Ignoring idempotency and exactly-once for external side effects.
- Treating AI as a black box without observability or evals.
Impact on Team & Organization
- Approved runtime, edge, and DB combination.
- Terraform/Cloud assemblies.
- Observability defaults like trace IDs and log schemas.
- Security policies and secret management.
- A minimal ticketless experience offering self-serve, but safe.
From the developer’s perspective, this results in faster delivery with fewer paper cuts. Although there is some loss of choice, the paved road is worth it.
What to Learn and Unlearn
The following table lists the concepts developers should learn and unlearn for serverless 2.0 development.
| Learn | Unlearn |
|---|---|
| Event-driven design, sagas, and compensation patterns. | Stateless only think that durable workflows change what’s possible. |
| Data locality strategies; consistency modes; CDC and materialized views. | One-region fits all assumptions because users and the app are global. |
| Observability triad (logs/metrics/traces) and workflow introspection. | As everything is designed for backpressure and retries upfront, unlearn the ” add the queue later attitude. |
| Cost awareness: egress math, AI token budgeting, cache TTLs. | |
| Prompt engineering basics and eval frameworks in case of AI. |
Conclusion
Serverless 2.0 is less about a single product than a default shift. In serverless 2.0, Compute is durable when needed, and data meets users where they are. The edge is part of the app and not just a cache layer.
Security in serverless 2.0 is not stapled but baked in. AI is a first-class primitive with governance. Most importantly, the developer experience finally feels like building an application, not assembling a data center in the cloud.
There are a few glue scripts, fewer pages, better latency, and a codebase that reads like business and not infrastructure. So, serverless 2.0 abstraction lets developers move faster and sleep better.
This is a platform that developers have always wanted, without owning it!
|
|