Serverless Computing in Software Engineering
Serverless computing is the technology that abstracts away server management so developers can focus purely on code and functionality. However, despite its name, “Serverless” doesn’t mean there are no servers. Instead, it refers to a cloud computing execution model in which the cloud provides dynamically managed infrastructure, resource allocation as required, and billing only for the actual usage.
| Key Takeaways: |
|---|
|
In this article, we will learn the following:
|
In this article, we will delve into the details of serverless computing to know more about its architecture, ecosystems, benefits, and challenges.
What Is Serverless Computing?
Definition
Serverless computing is a cloud-native application development and execution model that enables developers to build and run code in response to events without provisioning or managing servers or back-end infrastructure.
In serverless computing, the servers are managed by a cloud service provider (CSP) and are invisible to the developer, who doesn’t see, manage, or interact with them in any way.
Key components of serverless computing include:
- Function as a Service (FaaS): Code is executed in stateless, temporary functions triggered by events (e.g., HTTP requests, file uploads).
- Backend as a Service (BaaS): Third-party services such as authentication, databases, or storage abstract away backend logic.
Provisioning and Billing
With serverless computing, developers can focus only on writing the best front-end application code and business logic; CSP manages the rest once the application is deployed to a container.
Apart from provisioning the infrastructure required to execute the code and scaling the infrastructure up and down as needed, CSP is also responsible for all routine infrastructure management and maintenance, such as security management, capacity planning, operating system updates and patches, and system monitoring.
One distinguishing feature of serverless computing is that developers never pay for idle capacity. In serverless computing, pricing is based on execution time and resources required. When there is a demand, CSP spins up, provisions the resources, and spins them back down again (scaling to zero) when execution stops. The billing starts when execution starts and stops when execution ends.
The Serverless Ecosystem
The serverless ecosystem consists of the following main aspects:
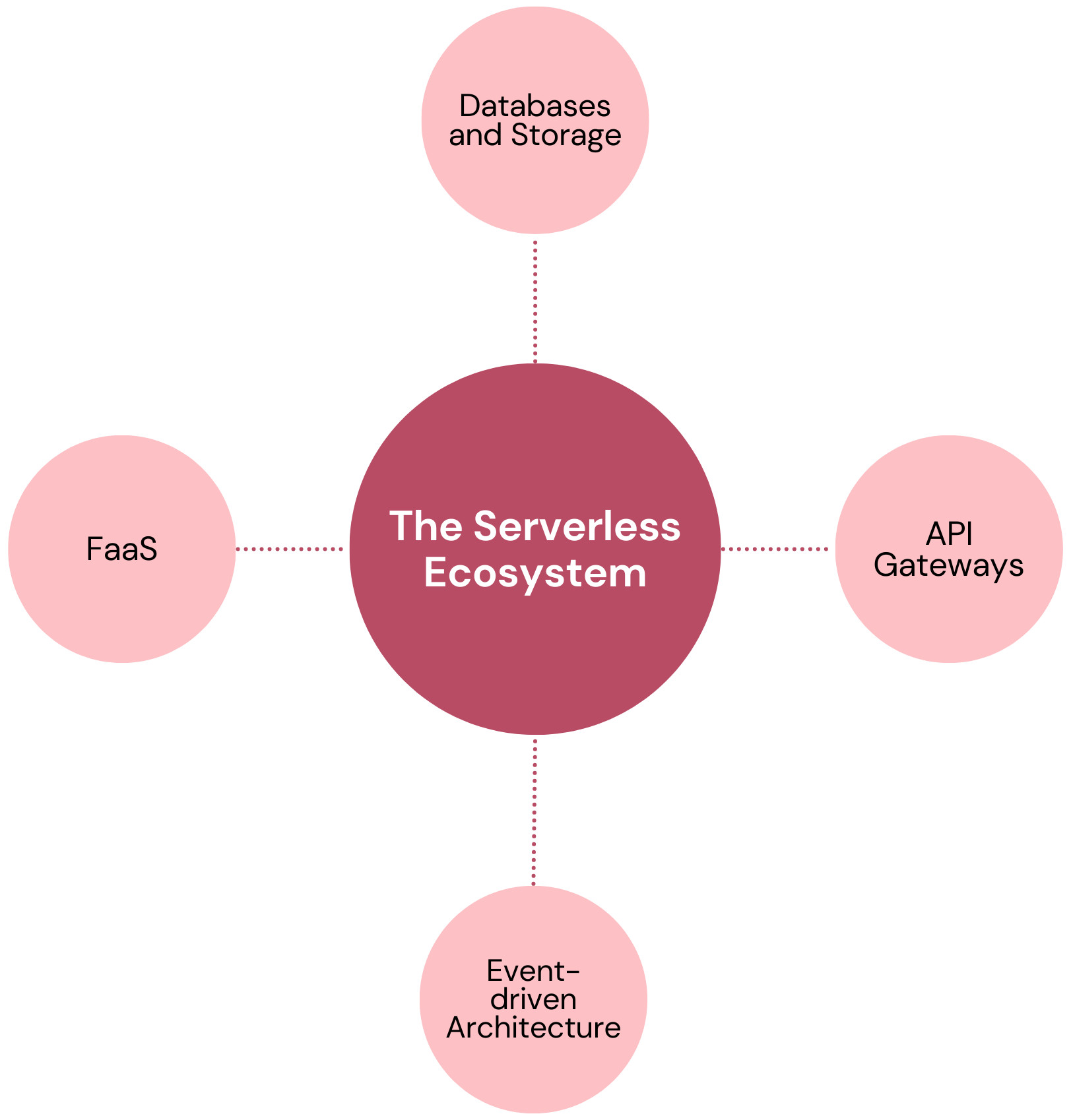
Serverless and FaaS
FaaS is a computing model central to serverless, though the two terms are often used interchangeably. FaaS consists of stateless functions that are executed in response to various events. Unlike FaaS, serverless is an entire stack of services that respond to specific requests or events and scale to zero when not used.
Serverless Databases and Storage
The foundation of data layers lies in databases (SQL and NoSQL) and storage (object storage). A serverless approach to databases and storage involves transitioning away from provisioning ‘instances’ with defined capacity, query, and connection limits and leaning toward models that scale linearly with demand in infrastructure and pricing.
API Gateways
Application Programming Interfaces (API) gateways are proxies to web application actions and provide functionality such as HTTP method routing, client ID and secrets, rate limits, CORS, viewing API usage, viewing response logs, and API sharing policies.
Serverless and Event-driven Architecture
Serverless architectures work well with event-driven workloads, specifically the open-source Apache Kafka event streaming platform. Automated serverless functions designed to handle individual events are essential to event-driven architecture (EDA). In the EDA framework, event producers like microservices, APIs, or Internet of Things (IoT) devices send real-time event notifications to event consumers, thus activating processing routines to service the event.
Serverless versus PaaS, Containers, and VMs
Serverless computing, platform as a service (PaaS), containers, and virtual machines (VMs) play essential roles in cloud application development and the compute ecosystem.
It is hence imperative to measure how serverless compares to the others across the key attributes, as shown in the following table:
| Key Attributes | Serverless Computing | Other Models(PaaS, Containers, VMs) |
|---|---|---|
| Provisioning time | Milliseconds | Minutes to hours |
| Administrative burden | None | Light to medium to heavy for PaaS, containers, and VMs, respectively. |
| Maintenance | Managed 100% by CSPs | Containers and VMs require significant maintenance. |
| Scaling | Autoscaling, including autoscaling to zero. | Automatic but slow scaling, no scaling to zero. |
| Capacity planning | None | Mix of automatic scalability and capacity planning. |
| Statelessness | Inherent, the state is maintained in an external service or resource. | PaaS, containers, and VMs can use HTTP, keep an open socket or connection for long periods, and store state in memory between calls. |
| High availability (HA) and disaster recovery (DR) | Offers both high availability and disaster recovery with no extra effort or extra cost. | Require extra cost and management effort. |
| Resource utilization | 100% efficient, as there is no idle capacity. | At least some degree of idle capacity. |
| Billing and savings | Metered in units of 100 milliseconds. | Metered by the hour or the minute. |
Serverless, Kubernetes, and Knative
Serverless applications are often deployed to a container. Kubernetes, an open-source container orchestration platform that automates container deployment, management, and scaling, only runs serverless apps independently with specialized software. This specialized software integrates Kubernetes with a specific CSP’s serverless platform.
Knative is an open-source extension of Kubernetes that provides a serverless framework. Using Knative, any container can run as a serverless workload on any cloud platform that runs Kubernetes. It abstracts away the code and handles the network routing, event triggers, and autoscaling for serverless execution.
Benefits of Serverless Computing
Serverless computing has various benefits listed as follows:
- Increased Developer Productivity: With serverless computing platforms, developers are not burdened with infrastructure management and maintenance. Thus, developers can focus on rapid prototyping, faster iteration, and a shorter development lifecycle. They can spend more time innovating and optimizing their front-end application functions and business logic.
- Scalability: Serverless applications automatically scale in response to demand. Whether serving 10 users or 10,000, the platform handles the necessary scaling without intervention.
- Pay Per Execution Only: The billing starts when the request is made and ends when execution finishes. This granular billing model eliminates the cost of idle resources, making it ideal for variable workloads.
- Simplified Operations: CSP handles Infrastructure management tasks. DevOps teams can focus on higher-value tasks such as performance tuning and deployment pipelines. Serverless simplifies deployment and DevOps.
- Event-Driven Architecture: Serverless applications in real-time to trigger events such as user actions, scheduled events, or data changes. It is well-suited to event-driven paradigms.
- Develop in Any Language: Developers can develop code in any language or framework—including Java, Python, JavaScript, and Node.js—that they’re comfortable with.
- Reduce Latency: Serverless computing environment reduces latency as code runs geographically closer to the end user.
Serverless Computing Use Cases
The following are the use cases of serverless computing:
Microservices
Supporting microservices architecture is the most common use case for serverless systems. The microservices model creates small services that perform a single job and communicate with each other using APIs. Building microservices using serverless systems has gained momentum because of the serverless features like small bits of code, inherent and automatic scaling, rapid provisioning, and a pay-as-you-use pricing model.
APIs and Webhooks
In a serverless platform, any action or function can be turned into an HTTP endpoint for web clients. These web actions can be assembled into a full-featured API with an API gateway that brings in OAuth support, rate limiting, custom domain support, and more security.
RESTful APIs can also be deployed faster using serverless functions.
Real-Time Processing
The custom responsiveness of real-time streaming engines is improved by serverless computing. Serverless apps can handle vast amounts of streaming data from numerous sources while experiencing low latency and high bandwidth. Hence, the processing time is in seconds instead of minutes.
Serverless functionality can also be used for clinical data analysis, for example, Genetech which uses AWS serverless functionality.
Disadvantages of Serverless Computing
Despite its advantages, serverless computing has the following limitations:
- Cold Starts: Also known as “Slow Startup”, a delay occurs when an inactive function is invoked after a period of inactivity. It can affect the performance and responsiveness of serverless applications in real-time environments.
- Limited Execution Time: Most serverless platforms impose a time limit on function execution. This is not suitable for long-running processes.
- Debugging and Monitoring: Debugging can be complex with serverless functions, as developers lack visibility into back-end processes. Specialized availability tools are required to monitor performance and trace failures.
- Vendor Lock-In: Each service provider offers unique capabilities and features. Thus, applications become tightly coupled with the APIs and features, making migration complex and costly.
- Complexity in Architecture: While individual functions are simple, managing many functions, such as version control and dependency management, can introduce architectural complexity.
- Less Control: In a serverless setting, third-party CSPs control servers. The organization has less control over the management of hardware and execution environments.
- Higher Cost for Running Long Applications: Long-running processes can cost more than traditional dedicated server or VM environments, as serverless execution models are not designed to execute code for extended periods.
Future Outlook
Serverless computing is making commendable progress with advancements in edge computing, integrations with AI/ML, and container-based FaaS models (e.g., AWS Lambda with Docker).
Serverless is expected to become a cornerstone in modern software engineering as tooling and ecosystem maturity increase. With innovations, it is expected to continue building scalable, resilient, and agile systems.
Conclusion
Serverless computing is a paradigm shift in software engineering. Offloading infrastructure management empowers developers to build scalable, resilient, and cost-efficient applications faster. Though there are challenges, the thoughtful adoption of this model and best practices can benefit developers.
As the cloud landscape continues to innovate, serverless is set to play an increasingly vital role in how software is built and operated. Using an end-to-end serverless platform is the best way to ensure organizations benefit from adopting serverless computing.
|
|