Strong Consistency in Databases Explained: Guarantees, Trade-offs, and Real-World Use Cases
In 2021, a major outage at Facebook (now Meta) caused WhatsApp, Instagram, and Facebook itself to go down for hours. While the root cause was a networking issue, what stood out was how systems across regions lost the ability to agree on the current state of services.
Some internal tools couldn’t even resolve basic data about system locations. Engineers were effectively “blind” because different parts of the infrastructure no longer had a consistent view of reality.
A few things keep engineers up at night, as this situation does.
In the initial years of working with distributed systems, consistency seemed like a yes-or-no thing. Either your system has it, or it doesn’t. Yet as time passed, layers began showing up. Not everything fits in neat boxes. Some choices bring gains on one side, losses on another.
Right at the extreme end stands strong consistency. What it offers feels weighty: a solid guarantee.
Every read returns the latest write. Every single time.
Simple? Sure.
Too simple? Maybe.
Yet when it comes to actual systems, particularly those spread across locations, making that promise costs far more than you’d expect.
Besides that, it forces decision-making into your hands.
| Key Takeaways: |
|---|
|
What Strong Consistency in Databases Actually Means
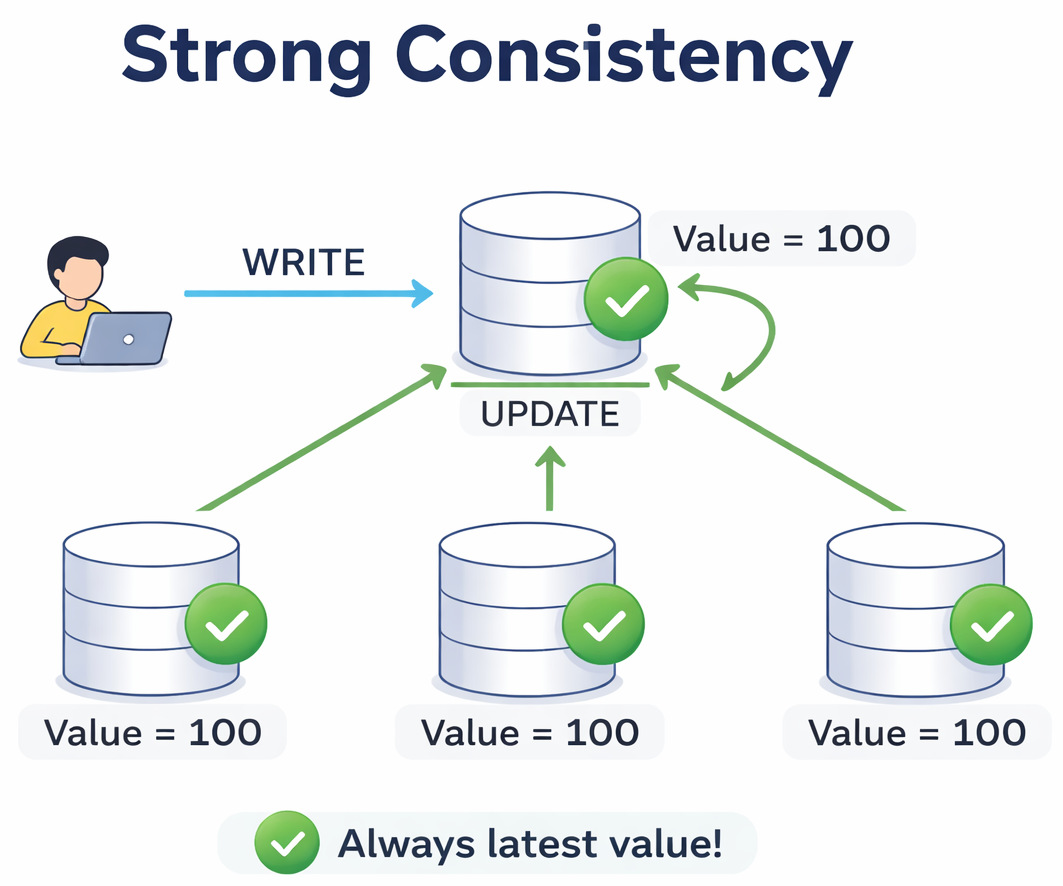
Keeping this simple.
Every time you save new information, the next time you look at it shows exactly what was saved. Without exception. What comes out matches what went in, every single time. Never different. Right away. This is strong consistency.
No “eventually.” No “after a few seconds.” Just… immediately.
Say you transfer money to your bank account. But the older amount still showed up when you checked the funds. It may have been only for one second, but that feeling of instant panic rising up your throat? (I know you know).
This is what strong consistency prevents. It makes sure that the system reflects reality every single time.
One thing to often consider: the system behaves like there is only one copy of the data, even if there are actually many copies behind the scenes.
Each step follows the last without exception. A chain forms, unseen but fixed. What happens next depends on what came before. Order rules, silent and total.
And that illusion is surprisingly hard to maintain.
Strong Consistency Compared to Eventual Consistency
Right now, maybe you have read a few articles on distributed systems. Chances are that pieces mentioned the clash between strong consistency and eventual consistency.
So let us first understand the meaning of both terms:
Strong consistency means that once a write is completed, every read will return the latest value; no exceptions. It is guaranteed that stale data will not be observed.
Eventual consistency, on the other hand, allows temporary differences between nodes. If no new updates are made, all replicas will eventually converge to the same value. It is accepted that outdated/obsolete data may be returned for a short period.
Example: One second, you share a post online. A second later, your pal refreshes their feed.
Right away, they spot your post – every single time (this is strong consistency). Not a moment later.
It appears – just not at first (this is eventual consistency). A short wait, then there it is.
A pause like that isn’t an error – more of a compromise made along the way.
Truth is, big systems often go for eventual consistency since speed and scale matter more. Yet this choice brings complications.
When teams treat small delays as harmless, reality hits hard – especially with payment systems, inventory, or stock tracking. It seems fine at first, yet problems pile up fast once timing affects critical steps.
This is when things quickly go out of hand.
Because strong consistency isn’t about being fancy; it’s about being correct when correctness matters.
Consistency Models in Distributed Systems And Where Strong Consistency Fits
Not every system needs strong consistency; it comes in many shapes across distributed systems.
Consistency models in distributed systems define the rules for when a write becomes visible to other reads. In other words, they answer a simple question: After I update data, when will everyone else see that update?
A few models hold tight to rules. Others move slowly, unbothered by limits.
Strong consistency, as previously said, is on one end of the scale. In fact, the strictest end. Linearizability is a fancy term that is frequently said in the same sentence as strong consistency. It merely means that everything happens in a neat, predictable manner.
On the other end, you have models like eventual consistency, where updates are propagated over time. Reads may return older values for a while, but the system eventually converges. Temporary inconsistencies are allowed in such systems.
There are also models in between. For example, causal consistency ensures that related operations are seen in the correct order, but unrelated operations might still appear out of order. Then there’s read-after-write consistency, which guarantees that you’ll at least see your own updates, even if others might not immediately.
Just straightforward stuff. Nothing odd edge case ever shows up. Everything stays predictable.
Frankly, it feels good to know that – especially for a developer.
Fresh data always shows up without having to wade through stale reads or conflicting states. Because it just works like you’d expect, every time.
But here’s the trade-off.
That simplicity at the application level comes at the cost of coordination behind the scenes. Systems now have to ensure agreement across nodes before responding.
Yet here’s the catch: making things simple for users often creates complexity somewhere else.
ACID Consistency versus Distributed Consistency (A Frequent Mix Up)
For quite some time, I didn’t get it – then I understood the difference. Now here’s the thing, spelled out straight. Strong consistency and ACID consistency are not the same.
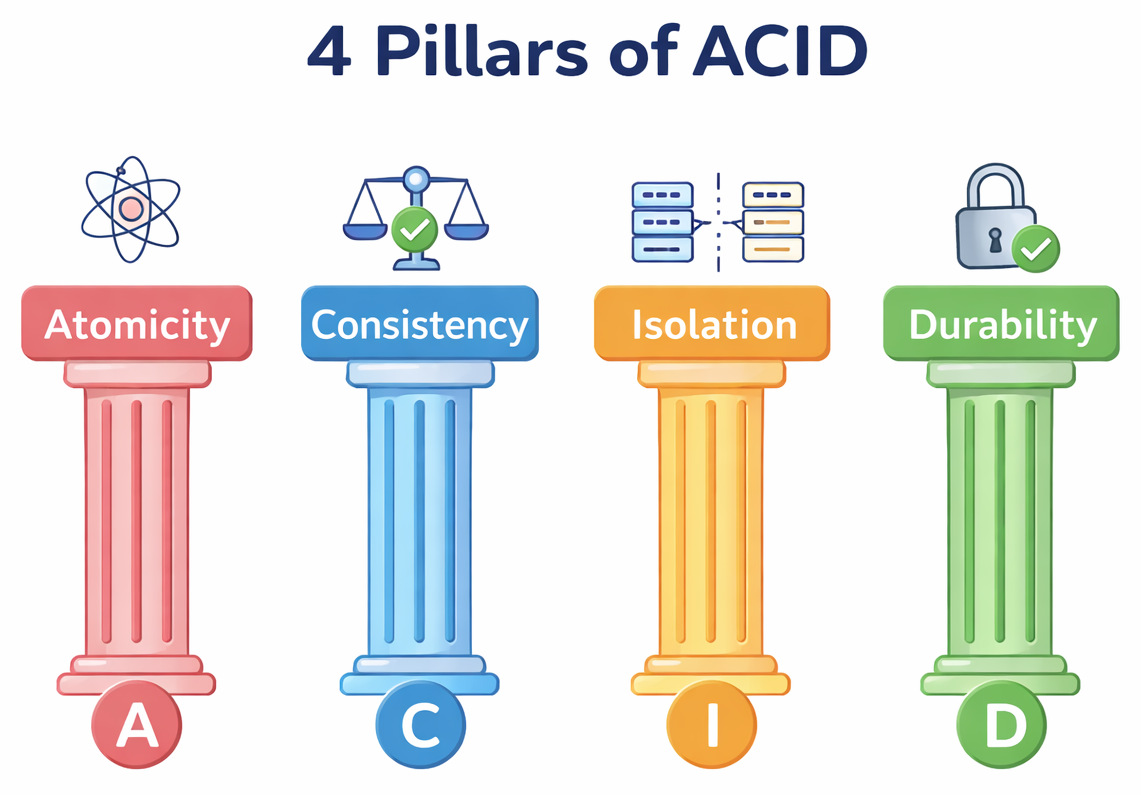
Let’s start with ACID.
- Atomicity
- Consistency
- Isolation
- Durability
- Atomicity makes sure that a transaction either fully completes or doesn’t happen at all (all-or-nothing). No partial updates. A transaction is either committed entirely or rolled back.
- Consistency ensures that the database moves from one valid state to another. Rules like constraints and schemas are enforced. Invalid data states are not allowed to persist.
- Isolation ensures that concurrent transactions don’t interfere with each other. Even if multiple operations happen at the same time, they behave as if executed one after another.
- Durability ensures that once a transaction is committed, it stays committed, even if the system crashes. Committed data is not lost.
So ACID is really about keeping data correct within a single database system, especially during concurrent operations.
What happens within a database during transactions ties back to ACID. Rules keep data correct, thanks to its safeguards.
Now, let’s contrast that with strong consistency.
Strong consistency is about what happens when your data is distributed across multiple nodes or machines. It makes sure that once a write is completed, all future reads, no matter which node they hit, return the latest value.
It is guaranteed that all nodes reflect the same state after a write.
- ACID → correctness of transactions inside a system
- Strong Consistency → agreement across multiple systems
This is why the confusion happens. Both aim for correctness, but at different layers.
And once you see that separation clearly, a lot of distributed system concepts start making more sense.
Even so, in most traditional databases, you get the two together, making them seem steady.
Read: SQL Database Concepts: Fundamentals Every Developer Should Know.
How Strong Consistency Works: Synchronous Replication and Consensus
When a system provides strong consistency, a write cannot be treated as complete after hitting just one node. It has to be replicated to multiple nodes and confirmed before success is returned.
This is called synchronous replication.
- The request goes to a primary node (often called the leader)
- The data is sent to other replicas
- The system waits until enough replicas acknowledge the write
Only then is the “write” marked as successful. The response is not returned until replication has been confirmed.
This ensures that no matter which node you read from next, you get the latest value.
But there’s another problem.
What if multiple writes happen at the same time? Or do nodes receive them in different orders?
This is where consensus algorithms come in.
- Which write happened first
- What is the current state of the system
Raft does this using a leader-based approach. One node acts as the leader, accepts writes, and replicates them to followers in order. If the leader fails, a new one is elected. A new leader is chosen automatically during failures.
Paxos solves the same problem but in a more abstract way, where nodes vote to agree on a value. It’s powerful, but honestly, harder to reason about.
The goal in both cases is the same:
Make sure every node applies the same writes in the same order.
This sounds simple, but in practice, it adds coordination overhead. Systems have to wait, messages have to travel, and delays start creeping in.
And that’s where the cost of strong consistency begins to show.
Strong Consistency Affects Speed and Access
Latency and availability are where reality sets in.
Let’s start with latency.
In a strongly consistent system, a write is not complete until it has been replicated and acknowledged by multiple nodes (often a majority). If those nodes are spread across regions, the request has to travel back and forth over the network before a response is returned.
The system is made to wait until coordination between nodes is completed.
For example, imagine a globally distributed database with nodes in India, the US, and Europe. A write might need confirmation from at least two regions before it succeeds. That round trip adds delay.
This sounds small, but in practice, it can mean the difference between a 50ms response and a 300ms response.
Users feel that.
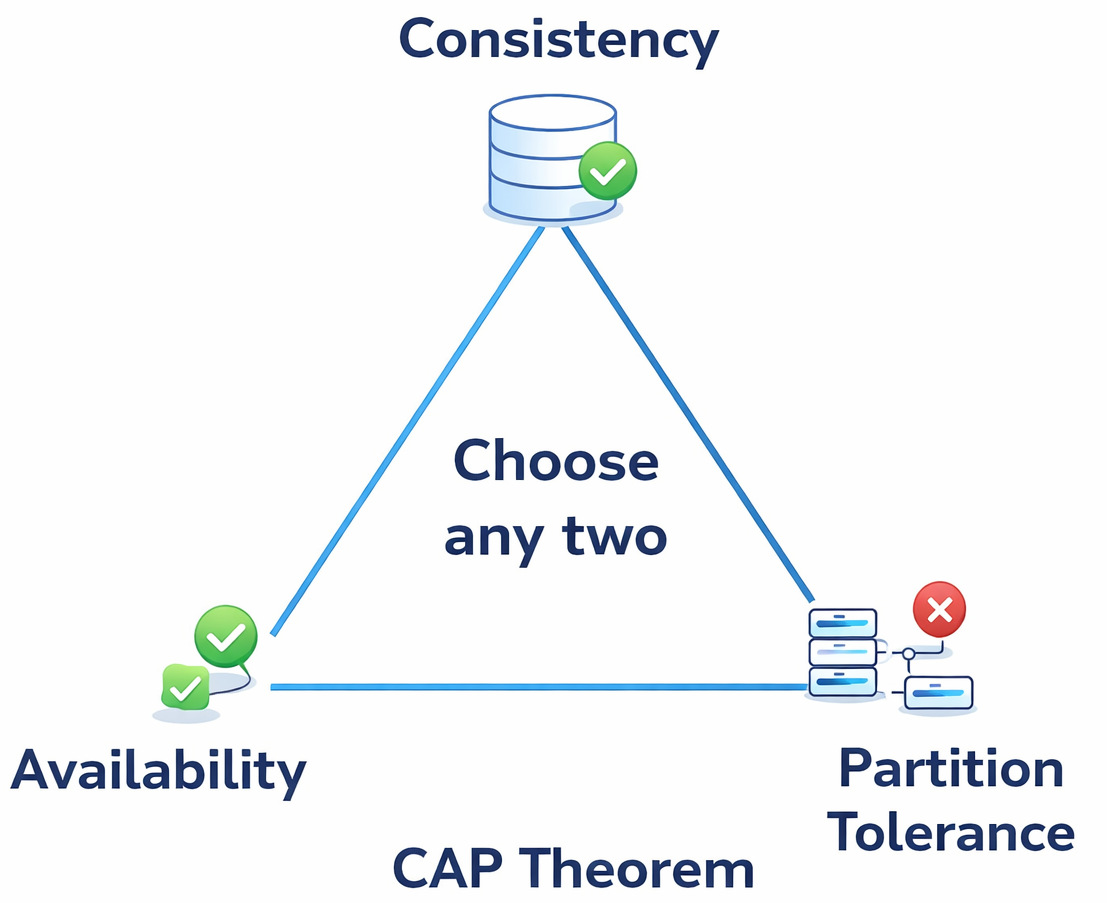
Now, availability.
Strong consistency systems often rely on quorum-based replication. That means a minimum number of nodes must be reachable to process reads or writes.
If enough nodes are down or there’s a network partition, the system may reject requests entirely.
Requests are denied to prevent serving stale or inconsistent data.
For example, in a 3-node setup, if only one node is reachable, the system might stop accepting writes because it cannot form a quorum.
This is exactly what the CAP theorem describes.
- returning possibly stale data (availability)
- or rejecting requests to preserve correctness (consistency)
Strong consistency chooses correctness.
And this is where teams often get caught off guard.
In real systems, this usually breaks during network failures. Everything is technically “correct,” but the system becomes unusable for a while.
That’s the trade-off: predictable data, at the cost of speed and access.
Real-World Use Cases of Strong Consistency
Let’s consider a realistic situation.
Take banking systems.
When you transfer money(say $500), the system treats it as a transaction: one account is debited, another is credited, and both must succeed together. Once the transaction is committed, every read must show the updated balance. The new state is made visible immediately across all nodes.
If one node shows $500 less while another still shows the old balance, that’s a failure.
Now, let’s take the example of stock trading.
When an order is executed, it is recorded and replicated across systems. Risk engines, portfolios, and market data must all see the same trade in the same order. A consistent sequence of trades is maintained across all systems.
If trades are delayed or processed out of order, positions can be calculated incorrectly, and even small inconsistencies can lead to financial loss.
Next up: e-commerce. Inventory shows up differently here.
Frustration hits when shopping online. Just as you go to pay, the item vanishes – marked unavailable. It happens more than you’d think. One second it’s there, the next it’s gone. Seemingly out of nowhere, a simple purchase becomes impossible.
This is a live example of how strong consistency works.
In its absence, one person could grab the final piece while another does too – sudden conflict appears. Resolving that complexity is a needless headache.
In real projects, it may fail as teams often neglect how much it costs to keep everyone on the same page.
Most of the time, they build systems expecting perfect sync to happen on its own. Yet real networks slow down, break, or grow too big – things often ignored early on. These gaps sneak in when least expected, revealing flaws hidden by optimism.
After a while, everything starts slowing down.
Users walked away from strong consistency when delays grew too much. Sometimes speed matters more than perfect sync.
Some scenarios where users might not agree with the above practices are that strong consistency simplifies your application logic, but pushes complexity into the infrastructure.
Most of the time, developers needn’t worry about weird edge cases – yet behind the scenes, there is still syncing, agreement across systems, plus coping when parts break.
The complexity is shifted rather than eliminated.
Understanding this trade-off matters more than most think.
An Analogy
Imagine a group of people trying to keep a shared notebook.
With strong consistency. Every time a person puts content down, others have to confirm they saw it – only then does another take their turn. Each note waits for acknowledgment before the next begins.
Falling behind isn’t an option for anyone.
This way, alignment is perfect.
Yet speed takes a hit too.
When to Use Strong Consistency (And When Not To)
What guides your choice?
What amount of inconsistency feels okay to you?
If the answer is “none,” you probably need strong consistency. Think banking transactions, stock trading, or payment systems, where even a small mismatch can lead to financial loss. Incorrect data is not acceptable in these cases.
If the answer is “a little is fine,” you might not. For example, social media likes, comment counts, or analytics dashboards can tolerate slight delays. A user seeing 101 likes instead of 105 for a few seconds doesn’t break anything. Temporary inconsistencies are acceptable in such scenarios.
After all, strong consistency isn’t tied to outdoing others. What matters is showing up when it counts.
And knowing that difference is what separates good system design from great system design.
Frequently Asked Questions (FAQs)
What is strong consistency in simple terms?
A: Strong consistency means that once data is written, every read will return that latest value, no waiting, no outdated data.
How is strong consistency different from ACID consistency?
A: ACID consistency is about keeping data valid inside a database transaction, while strong consistency is about making sure all distributed nodes show the same data.
Why is strong consistency slower?
A: As the system has to coordinate across multiple machines before confirming a write.
That means waiting for responses over the network.
|
|