Why RAG is the Backbone of Modern Enterprise AI Systems
Recent findings from the MIT NANDA initiative suggest that as many as 95% of enterprise generative AI initiatives do not achieve measurable returns on investment. While it might seem far-fetched initially, working with real systems makes you see the truth.
Truth is, putting together a demo takes almost no effort. And when it is released to real users. Everything starts breaking down.
Most early AI systems based on large language models (LLMs) looked impressive. Writing came easily to them, also shortening long texts, and sometimes thinking through problems too. Yet once placed into real business settings – like helping customers, finding legal rules, or digging up files internally – the flaws popped out. Things fell apart when tested where it actually mattered.
Wrong answers showed up now and then. Missing context made things harder to follow. At times, the system spoke with full confidence despite being completely wrong. Incorrect responses were being generated without any indication of uncertainty.
Here’s when Retrieval-Augmented Generation (RAG) began drawing interest, not because as a trend, but as a necessity.
| Key Takeaways: |
|---|
|
The Hidden Flaw in Large Language Models
LLMs are an incredible help to the masses. That’s clear enough. But they were never designed to be perfect knowledge systems.
One thing stops them early on. Your company’s private information is not available to them. And more critically, they don’t really do things. They just predict.
This makes them prone to making things up (hallucination).
Let us understand with an example. A team made a bot to handle questions about internal company policies. During testing, it ran without issues. Yet when staff began posing trickier versions of those same questions, cracks appeared. Responses sounded accurate, though they missed the mark entirely.
The shortcomings are often caught in real-time situations, when the model faces questions that are just slightly outside of what they have faced before.
This hits you suddenly, not some small glitch. A core flaw instead of an oversight.
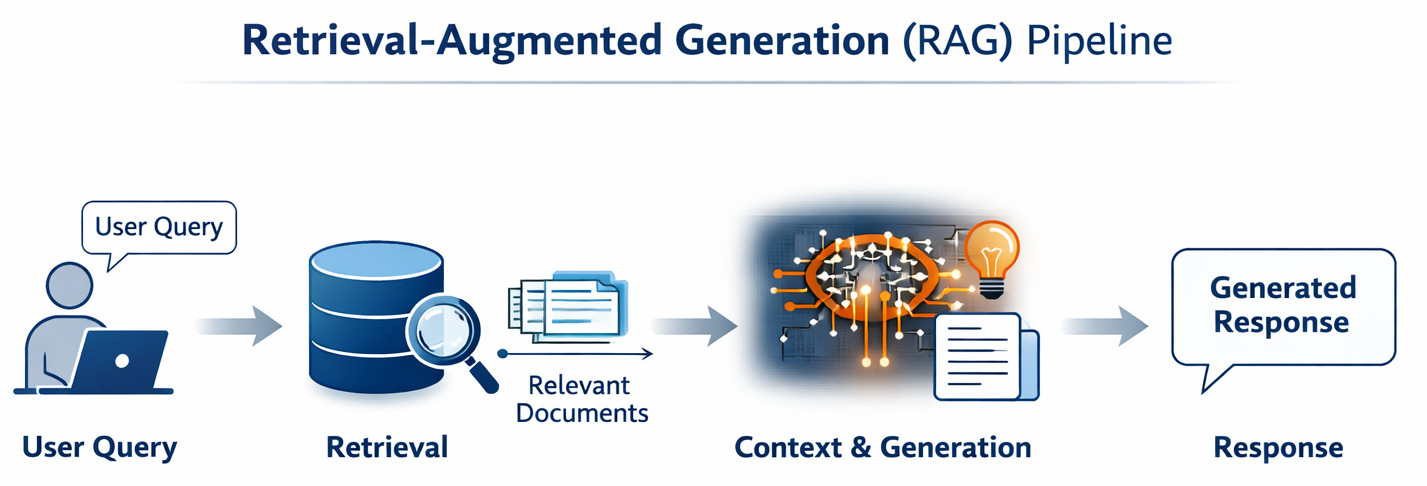
How RAG Shifts LLM Grounding and AI Knowledge Retrieval
Today, the LLMs don’t search memory first. RAG brings in a factor that LLMs were missing, i.e., grounding. So with this, the system doesn’t ask “what do I remember?”, rather it checks what information is relevant right now. This information is then passed into the model. The model is guided by the retrieved context before generating its response.
Accuracy improves because of the LLM grounding.
Yet most overlook this: RAG’s heavy lifting happens before the answer forms. Not in generating answers. But in finding them.
- Find the right documents
- Pull the right pieces
- Rank them correctly
RAG or Fine Tuning: Which One Works Better
Every so often, people argue about whether RAG works better than fine-tuning. Sometimes one wins, sometimes the other.
On paper, both seem right, but they help solve different types of issues.
Fine-tuning helps adjust how a model behaves. Whereas, RAG changes (updates) what it knows at that particular minute.
And to be honest, in most real-world scenarios, RAG has a clear upper hand.
| Aspect | RAG | Fine-tuning |
|---|---|---|
| Data updates | Real-time | Static |
| Cost | Lower | Higher |
| Flexibility | High | Limited |
Fine-tuned models are harder to update frequently. We have seen teams work to fine-tune models just to include updated documents. Does it work? It works initially… until the data gets modified/updated again. When this happens, the teams are stuck retraining.
Sounds perfectly fine in theory, but in practice, it is expensive and slow.
Makes sense as to why most modern systems end up relying on RAG for any scenario that involves dynamic knowledge.
Enterprise AI Architecture is Shifting Without Fanfare
RAG isn’t just a technique. It is now influencing the blueprint of AI architecture.
Previously, the model was the center of everything. These days, architecture is being built around retrieval.
- Data sources (documents, databases, APIs)
- A vector database
- A retrieval layer
- Next up comes the LLM
The system is structured in a way where retrieval happens before generation. What you find shapes what follows next. Before any output appears, something must be pulled from storage. The process moves step by step. Pulling data leads directly to creating responses. Nothing forms until information arrives.
When it comes to business settings, being correct and traceable counts for far more than the speed of raw generation ability.
You can read: Code Generation: From Traditional Tools to AI Assistants.
Vector Database Integration and Semantic Search for LLMs
Vector databases are worth mentioning here as it rarely gets any sort of the rightful attention they deserve. These systems store embeddings; basically, numerical representations of text. This allows the system to search based on meaning, not just keywords.
Now it looks at the intent, not just the words you type.
A person could say, “I can’t log in anymore.” Then the system retrieves something called: “Steps to recover your password.”
Relevant information is retrieved based on semantic similarity. What you get depends on how ideas match up. Meaning links what shows up next. This is how LLMs handle semantic search, part of why RAG performs effectively.
Still, there’s no magic at work here.
When a project begins, things often fail, especially if the data lacks clarity or files are disorganized.
Reducing AI Hallucinations (Without Full Elimination)
What stands out most with RAG is how it cuts down on hallucinated answers.
Yes, it actually works. Quite well, too.
With real context, the model makes up things way less. The generated output is constrained by the provided data. But let’s be realistic for a second. Hallucinated answers still slip through, even with RAG in place.
Wrong information pulled up means the response fails, even if everything else works right. This is the reason you might hear someone mention:
“RAG shifts the problem from generation to retrieval.”
Additional resource: What is Agentic Coding?
RAG Pipeline Optimization: Where Problems Happen
In truth, most RAG systems usually don’t fail due to LLM; they fail quietly due to the pipeline around it. Theoretically, the concept is pretty solid: retrieve → augment → generate.
- Wrong Context by the Retrieval: This is the most common failure scenario. The system retrieves documents, the similarity seems fine, but still, it doesn’t feel right. Relevant-looking documents are retrieved, but they may not fully answer the query.
How does it happen? It’s usually because embedding doesn’t understand the intent, vague or underspecified queries, and chunking disturbs the semantic continuity.A common way to solve this is to add a re-ranking step, use hybrid search (i.e., semantic + keyword), and implement a better chunking strategy so that meaning isn’t split.
- Excessive Context (Context Window Mismanagement): This is a more sneaking version of the issue. You retrieve several chunks, transfer them into LLM, and expect good answers. But instead, you notice that the quality has decreased.
Why does it happen? Mostly due to the LLM not “prioritizing” the context properly, important signals get diluted, and token limits have been crossed.The context window mismanagement issue can be first acknowledged by acknowledging that more context doesn’t mean a better answer. Second is to restrict to top high-quality chunks (not quantity, but quality). Use context compression or summarization, and also make sure to structure prompts in a manner that important data is at the start.
- Improper Document Chunking: This issue doesn’t stop at errors; it degrades everything. Retrieval quality steadily degrades. Chunks are frequently generated without maintaining logical boundaries. Sentences are split mid-way, tables or codes get broken apart, and context is distributed across multiple chunks.
It is usually resolved by shifting from fixed chunking to semantic or recursive chunking. Make sure to add relevant overlap (never too much) and keep chunks self-contained.It is always advisable to check this scenario first when you feel the RAG system feels “inconsistent”.Latency spikes and hallucinations are other common scenarios where the RAG system gets affected. It is advised to reduce embedding size, use approximate nearest neighbor (ANN) search, stay away from over-engineering, use citations in prompts, stricter prompting, and filter retrieved chunks.
What are the Different Types of RAG Architectures?
So, these architectures are divided into 4 main categories:
| Architecture | How Retrieval Works | Strengths | Limitations | Best Use Cases |
|---|---|---|---|---|
| Standard (Vanilla) RAG | Retrieval happens once before generation; results are appended to the prompt | Simple, fast, easy to implement | Struggles with complex or evolving queries | FAQs, basic chatbots, simple Q&A systems |
| Iterative (Recurrent) RAG | Retrieval happens multiple times during generation; the model can re-query | Better reasoning, adapts mid-response | Higher latency, more complex pipeline | Multi-step reasoning, research assistants |
| Hierarchical RAG | Retrieval occurs in layers (document → section → paragraph) | Efficient for large datasets, better precision | More engineering effort is required | Legal docs, technical manuals, long reports |
| Graph-Based RAG | Uses knowledge graphs to retrieve entities and relationships | Highly structured, more explainable | Hard to build and maintain | Enterprise knowledge systems, scientific data |
Where each of these architectures gets used is a question that pops up often.
Well, most firms do start with the standard version, simply because it is easier to deploy. Iterative RAG makes more sense than standard when complex queries are in play, or the user demands multi-step reasoning. And Hierarchical or Graph-based RAG are the smarter choice if you are working with interconnected data (say, medical or legal) or just massive volumes of documents.
Document Chunking Strategies: Small Detail, Big Impact
This sounds like an insignificant detail, but it holds great weight.
Before the files get stored, they are broken down into smaller pieces (chunks). The way they’re broken down plays a bigger role than most realize.
Documents are divided into smaller segments before being indexed. There are multiple methods for chunking strategies. The most popular ones are explained in the table below.
| Strategy | Definition | Best For | Risk |
|---|---|---|---|
| Fixed-size | Splits text into equal-sized chunks based on token/character limits, without considering meaning | Quick prototypes, simple use cases | Context gets cut off mid-thought |
| Sliding Window | Creates overlapping chunks so that adjacent chunks share some content | Preserving context across boundaries | Redundancy increases, and retrieval can get noisy |
| Semantic | Splits text based on meaning, grouping sentences or paragraphs that are semantically similar | High-quality retrieval, knowledge-heavy systems | Hard to tune and define clear boundaries |
| Structure-based | Uses document structure like headings, sections, or formatting to create chunks | Well-structured documents (docs, manuals) | Breaks when documents are unstructured |
| Recursive | Applies multiple strategies in sequence (e.g., section → paragraph → token) until chunk size is acceptable | Production systems with varied data | More complex to implement |
| Query-aware | Dynamically selects or forms chunks based on the user’s query | Advanced, highly contextual systems | Increased complexity and latency |
A Quick Reality Check
It is towards the end of the blog; let’s be honest.
RAG works well. Yet it won’t fix everything.
- More complexity
- More moving parts
- More things that can go wrong
This might seem fine in theory, yet actually making a reliable RAG setup requires real work.
So… is RAG Actually the Core?
Maybe. Because it fixes something fundamental.
- Accurate information
- Up-to-date data
- Context awareness
RAG makes it happen, after all.
These days, lots of AI setups rely on retrieval. Retrieval methods sit at the core of many current models. Getting facts back helps power recent advances in machine learning.
Final Thoughts
Beyond basic prototypes, limits show up fast when working with large language models. A project grows, then its boundaries become obvious almost right away.
Once that happens, finding methods to boost their dependability becomes a natural next step.
This is typically the moment RAG shows up.
It isn’t a bonus feature – it’s what keeps things running.
RAG changes more than performance; it brings AI into everyday life.
This is why it’s becoming the backbone of modern AI.
Frequently Asked Questions (FAQs)
Does RAG completely eliminate AI hallucinations?
A: Well, not really. It reduces them a lot, but doesn’t eliminate them 100%. If the retrieved data is wrong or irrelevant, the output will still be off. The quality of the response is heavily dependent on retrieval accuracy.
Do I always need a vector database for RAG?
A: Not mandatory, but in most cases, yes, it makes things much more effective. Vector database integration helps with semantic search, which is kind of the backbone of good retrieval.
How does context window management affect RAG performance?
A: A lot more than people expect. We can’t just pass everything into the model, it has limits. So, choosing what context to include becomes important.
|
|