Does Using AI for Code Generation Actually Save Time?
Our story
Naturally with the rise of AI and recent model improvements, we wanted our own team to increase their use of AI so that we could become more efficient and demonstrate an ROI.
So we asked our engineers to start using AI in their work, especially around code creation. So some of our most experienced engineers tried some of the best tools on the market. The result? We got a strong negative response from all of them.
After some evaluation, they said that they’d rather do it themselves because they found that they were spending more time cleaning up the AI generated code and redoing it.
Is our experience a fluke? Or is this a problem that’s common?
Apparently, pretty common as the following research shows.
Studies: AI-based code generation slows down engineering
People expect improvement of performance from AI code generation but actually it slows them down by 19%, as measured by Model Evaluation and Threat Research.
They did a thorough scientific study with 16 experienced developers each with over 10 years of experience, working on 246 tasks for 21 different open source projects. Those tasks were divided randomly with some where they were not allowed to use AI, and others where they were required to use AI. The AI used was mostly Cursor Pro with Sonnet model.
While working, each engineer was recorded on Zoom calls and then carefully analyzed to break down specific activities for further analysis. After the study, engineers were surveyed on what they expected the AI effect would be and asked whether they were faster or slower using AI. The results were very surprising: on average the engineers expected the AI to help to complete tasks 20% faster, but in reality they were completed on average 19% slower.
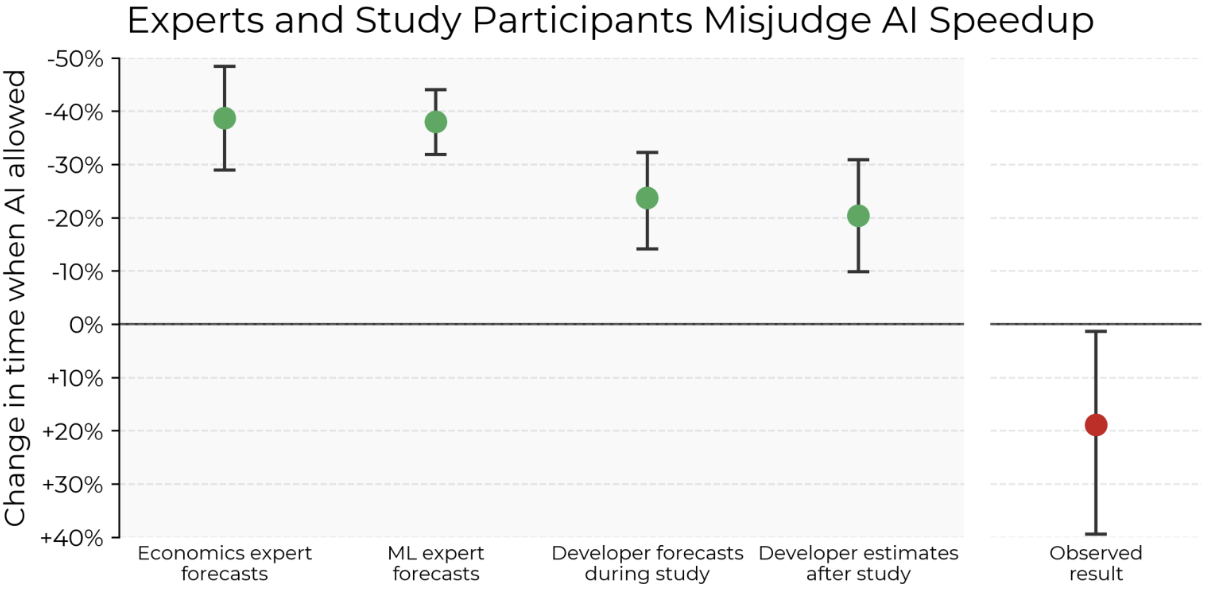
But why?
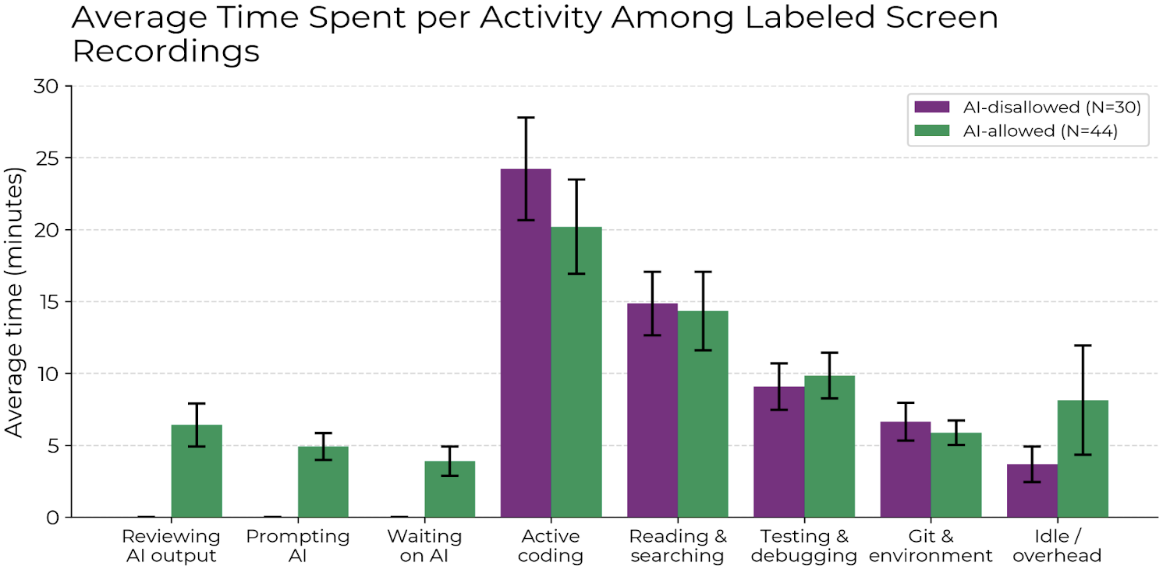
Based on the research (see the picture above) it is mostly because:
- There were added activities like:
- Prompting AI
- Waiting for AI (an extreme waste of engineering time!)
- Reviewing AI output
- One would expect the code generation to almost eliminate the need to actively write code, but it only made a very slight improvement compared to not using AI at all.
Those factors were the key contributors (based on the observation above) to the negative ROI of using AI for generating code.
Where is this slowness of delivery with AI coming from?
All of the issues are basically the attributes of AI hallucinations. Based on very recent research by OpenAI on the source of hallucinations, the models are trained to have a “reward” step function that rewards only successful results and does not provide any reward either to admitting to not knowing the answer or a wrong answer. Thus, AI models are trained to be eager to provide an answer even if it is incorrect.
Incredibly, this means that the solution to these hallucination issues often doesn’t help with code generation since instead of saying it doesn’t know how to create the code in the correct way, it provides a hallucinated solution which doesn’t actually work. Because of this, the engineer needs to go back and spend more time fixing the code, creating lost ROI.
OMG! What do I do about it?
Essentially, the only way to get value from AI code creation is to learn how to deal with the hallucinations in the first place. How? We have to validate that what was delivered is working as expected? How? By running end-to-end tests.
That’s why we created codeCake. It was initially for our own team, then we realized it worked so well that others would get a huge benefit from it as well.
How does codeCake do it?
codeCake provides a way to build runnable end-to-end test cases in plain English before engineers even write the code.
Which means that the AI can iterate on code generation until the result is passing the end-to-end test provided.
Specifically it works like this:
- You provide an end-to-end test written on codeCake alongside a description of what needs to be done and reference to a Jira ticket.
- codeCake will generate the code based on the information provided above.
- If code doesn’t compile – an error will appear in logs and AI will work to correct it.
- If code doesn’t pass linter – again, an error would appear and AI will correct it.
- Then it will automatically run the test again.If code doesn’t run – once again, an error will appear and the AI will once again correct it.
- Then the end-to-end test that you provided will run on the locally deployed version of the code.
- If the test doesn’t go through, the system will provide feedback with screenshots to the AI and trigger it to correct the issues.
- This process will repeat these iterations until AI will correct all of its mistakes and produce the code that complies with the provided end-to-end test case.
- After which it will kick off a Pull Request.
- Once the Pull Request comments are provided, you can click a button to trigger AI to address these comments.
Thus, codeCake provides code that actually works and the way to communicate with that code is through code review comments, updates to the test case, or direct instructions to AI.
Now, our team is saving about 37% of their time using AI because of this process.
|
|
September 21, 2025
|