Understanding CPU Scheduling: Types, Metrics & Examples
If you’ve ever researched operating systems or built a backend system that handles many tasks at once, you’ve probably come across CPU scheduling algorithms. At first glance, these methods seem basic, just theoretical models. Pick the next process, run it, repeat.
However, most times, whether it’s a cloud server processing API requests or a mobile device juggling background apps, the scheduler decides how responsive the system feels.
Think of this as your phone running updates while playing music. Someone has to decide which task gets attention first. That job belongs to the scheduler. If it picks tasks badly, delays creep in without warning. Some programs might never get their turn. A poorly chosen scheduling strategy can increase latency, waste CPU cycles, or cause some processes to wait forever.
We will have a look at the four common ways: First Come First Serve, Shortest Job First, Round Robin, and then Priority Handling. Each method handles waiting time differently. We will also explore related concepts like Turnaround Time in OS, Convoy Effect, fairness in scheduling, and context switching overhead in Round Robin (RR).
| Key Takeaways: |
|---|
|
Understanding CPU Scheduling Basics
Before diving into algorithms, it helps to understand what a scheduler actually improves.
A CPU scheduler decides which process from the ready queue runs next. Its goal is not just fairness; it’s also about balancing multiple performance metrics.
Key Performance Metrics in Scheduling
| Metric | Meaning |
|---|---|
| Average Waiting Time | Average time processes wait before execution |
| Turnaround Time in OS | Total time from process arrival to completion |
| Response Time | Time taken before a process starts responding |
| CPU throughput | Number of processes completed per unit time |
| Fairness in scheduling | Ensuring all processes get reasonable CPU access |
A scheduler must balance these metrics. Improving one often worsens another.
- Reducing the average waiting time might hurt fairness.
- Maximizing CPU throughput may increase response time.
- Preventing starvation might add extra scheduling complexity.
And this is exactly where scheduling algorithms differ.
Read: Process vs. Thread: Key Differences Explained with Examples.
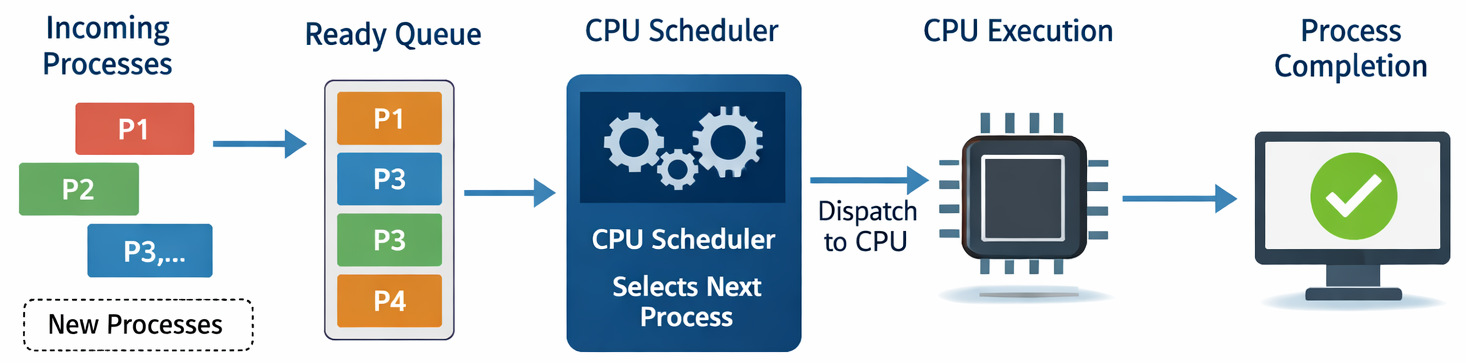
FCFS Scheduling and the Convoy Effect
First Come First Serve (FCFS) is the most basic scheduling algorithm. Processes are executed in the order they arrive in the ready queue.
Think of it like standing in the billing line at a grocery store. Whoever arrives first gets served first.
- Process enters the ready queue
- CPU selects the earliest arrival
- Process runs until completion
- Next process begins
It’s simple and easy to implement.
Example
| Process | Burst Time |
|---|---|
| P1 | 12 |
| P2 | 3 |
| P3 | 4 |
Execution order:
P1 → P2 → P3
The Convoy Effect Problem
The major disadvantage of FCFS is the Convoy Effect. Teams encounter this when a long process blocks several shorter ones.
Imagine a database backup process starting first and taking 30 seconds, while smaller API requests, which take significantly less time, arrive afterward. Those requests must wait the entire time.
The result is not only poor system responsiveness but also a high average waiting time. While acceptable on paper, it creates major delays in practice for interactive systems.
A restriction that teams often overlook is that many engineers assume FCFS will work because it is “fair.” But fairness alone doesn’t guarantee performance.
In high-traffic servers, FCFS can lead to request queues piling up quickly.
If there are very small workloads, systems with similar job sizes, or batch processing systems, it is when FCFS actually works well. But modern operating systems rarely rely on FCFS alone.
Shortest Job First and Optimizing Average Waiting Time
Shortest Job First (SJF) aims to address the waiting time problem in FCFS.
Instead of executing processes in sequential order, SJF chooses the process with the smallest CPU burst time.
Why SJF is Theoretically Optimal
SJF minimizes the average waiting time among non-preemptive scheduling algorithms.
Think of this example:
| Process | Burst Time |
|---|---|
| P1 | 10 |
| P2 | 3 |
| P3 | 2 |
Execution order under SJF:
P3 → P2 → P1
Short processes get completed quickly, reducing the waiting time for most tasks.
Preemptive vs. Non-Preemptive SJF
| Type | Behavior |
|---|---|
| Non-preemptive | Process runs until completion |
| Preemptive (SRTF) | A shorter arriving job can interrupt the current process |
The preemptive version is called Shortest Remaining Time First (SRTF).
The Starvation Problem in SJF
Here’s the disadvantage to this method.
Long jobs might never get CPU time if short jobs keep arriving. This is the classic case of starvation in Operating Systems.
In real projects, this creates a ruckus because a service receives a continuous stream of small requests.
Background jobs that require longer execution: data processing, reporting tasks, and backups. These will remain stuck in the queue. That’s why real-world schedulers introduce mechanisms like aging, gradually increasing priority for waiting processes.
Why SJF is Difficult to Implement
Another challenge: the system must know the future burst time.
In reality, that’s rarely possible.
Operating systems approximate this using historical execution patterns.
Read: Queue in Data Structures: A Complete Guide with Types, Operations & Examples.
Round Robin Algorithm and Time Slice Optimization
The Round Robin Algorithm is developed for time-sharing systems (where fairness and responsiveness are important).
Instead of letting a process run until completion, each process gets a fixed time slice (time quantum).
If the process doesn’t complete within that time, it’s simply booted to the back of the queue.
How Round Robin Works
- Each process gets CPU for q milliseconds
- If unfinished -> returned to queue
- Next process runs
Example with Time Quantum = 2
| Process | Burst Time |
|---|---|
| P1 | 5 |
| P2 | 4 |
| P3 | 2 |
Execution order:
P1 → P2 → P3 → P1 → P2 → P1
Why Round Robin improves fairness
Round Robin ensures every process gets a chance to execute regularly.
This significantly improves the response time vs. wait time balance.
Interactive applications benefit the most from this practice.
Context switching overhead in RR
Compromise still exists.
Each change between processes demands saving and restoring CPU state.
This is known as context switching overhead in RR.
If the time slice is too small, the CPU spends more time switching than executing tasks.
Time slice optimization
Selecting the right time quantum is crucial.
| Time Quantum | Result |
|---|---|
| Too small | Excessive context switching |
| Too large | Behaves like FCFS |
| Balanced | Good responsiveness |
While it sounds good in conversation, in practice, teams often underestimate how workload patterns affect the optimal quantum.
- Web servers benefit from small quanta
- Data processing jobs benefit from larger quanta
Finding the right balance is often done through benchmarking.
Priority Scheduling and Preemptive Priority Scheduling
In Priority Scheduling, each process is assigned a priority value.
The CPU always executes the highest-priority process first.
How Priority Scheduling Works
| Process | Priority | Burst |
|---|---|---|
| P1 | 3 | 5 |
| P2 | 1 | 4 |
| P3 | 2 | 6 |
Execution order:
P2 → P3 → P1
Lower numbers usually mean higher priority.
Preemptive Priority Scheduling
In Preemptive Priority Scheduling, if a higher-priority process arrives, it disturbs the currently running process.
- Real-time operating systems
- Embedded systems
- Interrupt-driven architectures
Starvation Risk: The biggest disadvantage is again Starvation in Operating Systems. Low-priority tasks may never run.
Real-world Solution: Aging
Operating systems gradually increase the priority of waiting processes. Fairness while still respecting priority. At times, teams may underestimate that priority systems can become difficult to maintain when priorities are assigned manually.
In large systems, developers often abuse priority levels. Due to this abuse, everything becomes a high priority, defeating the purpose of scheduling.
Response Time vs. Wait Time: What Should You Optimize?
A common misconception is that bringing down Average Waiting Time automatically optimizes performance. But for many applications, response time matters more.
Consider these scenarios:
| System Type | Most Important Metric |
|---|---|
| Interactive apps | Response time |
| Batch systems | CPU throughput |
| Real-time systems | Deadline guarantees |
This explains why operating systems rarely depend on just one algorithm.
Rather, they mix strategies.
Read: Engineering Metrics That Drive Software Success.
Multilevel Queue Scheduling in Modern Operating Systems
Modern systems often use Multilevel Queue Scheduling.
Processes are segregated into different queues based on type.
Example structure:
| Queue | Typical Processes | Scheduling Strategy |
|---|---|---|
| System Queue | OS tasks | Priority Scheduling |
| Interactive Queue | User applications | Round Robin |
| Batch Queue | Background jobs | FCFS |
Each queue has its own scheduling policy.
Why this Approach Works Better
It allows systems to optimize scheduling for different workloads. Interactive tasks stay responsive while background jobs still make progress.
Where it may fail in real projects is when queue classification rules are poorly defined.
Think of an example where a background analytics job accidentally ends up in the interactive queue and consumes excessive CPU time.
Schedulers must carefully scrutinize and manage queue boundaries.
Highest Response Ratio Next (HRRN): A Balanced Alternative
Another interesting and important algorithm is Highest Response Ratio Next (HRRN).
It calculates priority using the formula:
Response Ratio = (Waiting Time + Burst Time) / Burst Time
This balances short and long processes.
In this method, short jobs still get priority, but long jobs gain priority as they wait longer.
Why HRRN Matters?
It brings down starvation while still improving waiting time.
Many people believe that HRRN is a compromise between SJF and fairness in scheduling.
Comparing FCFS, SJF, Round Robin, and Priority Scheduling
| Algorithm | Best For | Major Advantage | Major Problem |
|---|---|---|---|
| FCFS | Batch systems | Simple implementation | Convoy Effect |
| SJF | Short workloads | Minimal Average Waiting Time | Starvation |
| Round Robin | Interactive systems | Fairness and responsiveness | Context switching overhead |
| Priority Scheduling | Real-time systems | Important tasks run first | Starvation risk |
Each algorithm optimizes a different goal.
Which CPU Scheduling Algorithm Should You Choose?
I think it’s quite clear that there is no ultimate winner. The right choice depends on system requirements.
- Batch processing dominates, and workloads are similar
- Simplicity is required
- Job lengths can be predicted
- Reducing the average waiting time is the priority
- Fairness is necessary, and the system supports interactive users
- Balanced response time vs. wait time is needed
- Critical tasks must run first
- Real-time constraints exist
The Real Lesson Behind Scheduling Algorithms
If there’s one takeaway from studying CPU scheduling, it’s this:
No single algorithm works perfectly in all scenarios or is the ultimate winner for an organization.
- Multilevel Queue Scheduling
- Priority adjustments
- Dynamic time slice optimization
This hybrid approach helps ensure all necessary factors, such as fairness, high CPU throughput, low response times, reduced starvation, etc.
And that’s why understanding these algorithms isn’t just theoretical. It helps you design systems that scale, stay responsive, and behave predictably under load.
Frequently Asked Questions (FAQs)
What is the difference between Average Waiting Time and Turnaround Time in OS?
A: Average Waiting Time measures how long a process stays in the ready queue before getting CPU time.
Turnaround Time in OS, on the other hand, measures the total time taken for a process to complete, including both waiting and execution.
The formula is:
Turnaround Time = Completion Time - Arrival Time
Waiting Time = Turnaround Time - Burst Time
In performance optimization, reducing Average Waiting Time often improves system responsiveness, but it doesn’t always guarantee better CPU throughput.
What is Multilevel Queue Scheduling, and why do modern operating systems use it?
A: Most modern operating systems don’t rely on just one scheduling algorithm.
Instead, they use Multilevel Queue Scheduling, where processes are grouped into separate queues based on their characteristics.
What is the Highest Response Ratio Next (HRRN) scheduling?
A: Highest Response Ratio Next (HRRN) is a scheduling algorithm designed to balance fairness and efficiency.
It calculates a priority value using:
Response Ratio = (Waiting Time + Burst Time) / Burst Time
Processes that have waited longer gradually gain higher priority.
This helps prevent starvation, which can occur in algorithms like Shortest Job First.
HRRN is particularly useful in systems where both short and long jobs must be handled fairly.
|
|