Why AI Reliability Depends on Strong Consistency (Not Just Better Models)
Let us imagine that you are using a simple AI tool at work. Nothing out of the box, just a modest RAG-based assistant with access to company policies. To test it, you asked it a simple policy-related question. You get a confident answer. You pose the same question again.
And voila, you get a different answer.
And not a near-adjacent answer, a completely different one.
It became clear to you that the problem wasn’t intelligence. The system clearly knew what it was being asked to do. But could you rely on its answer?
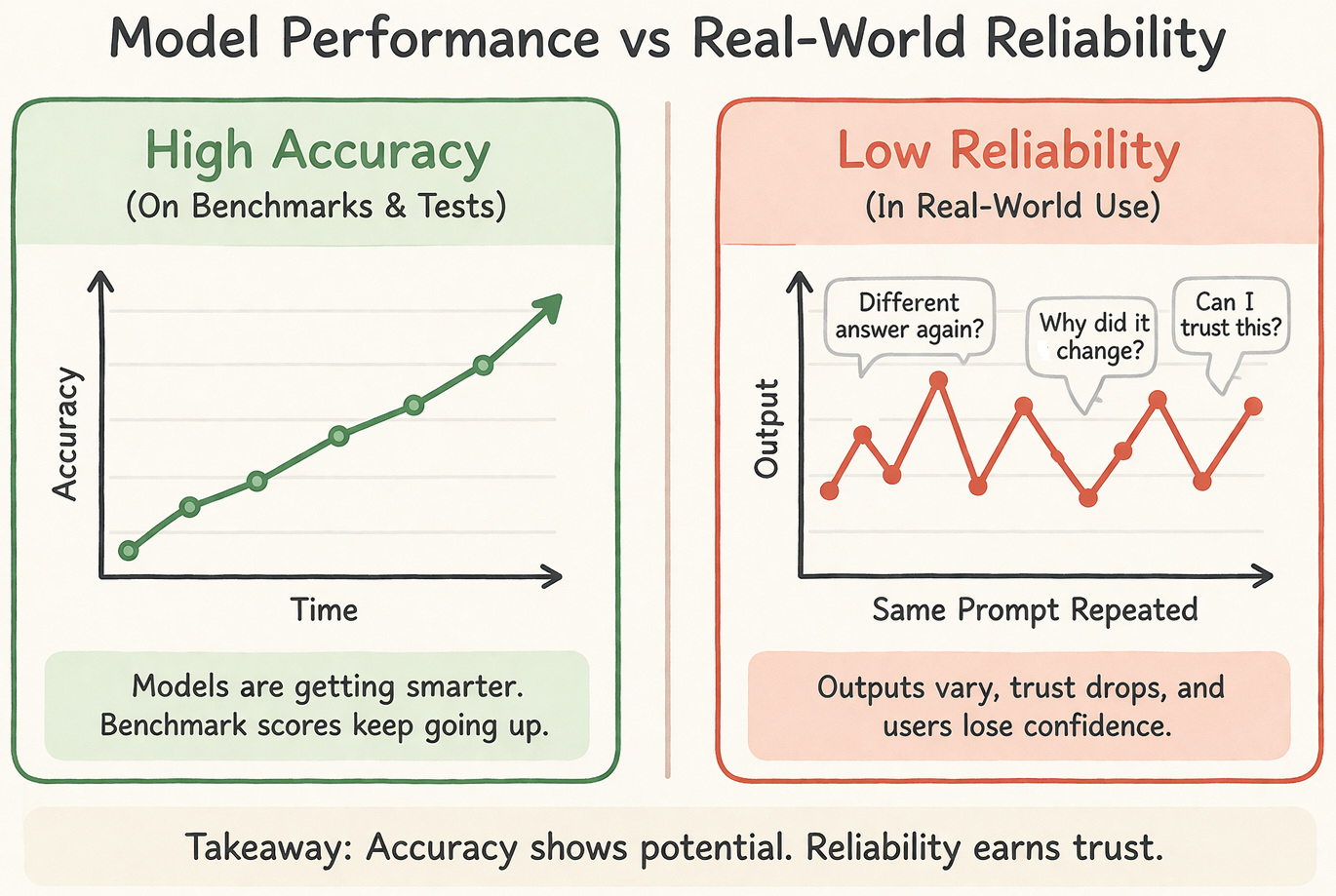
It may shock you to know that a large number of AI systems fail when they are tested in production. But you need to understand that it was not because the system was not intelligent enough.
No, it was because the system was not consistent enough. Many users wrongly assume that improving the model can solve these problems. This is simply not the case.
Let’s take a quick look at what really matters.
| Key Takeaways: |
|---|
|
AI Reliability vs. Accuracy (A Common Confusion)
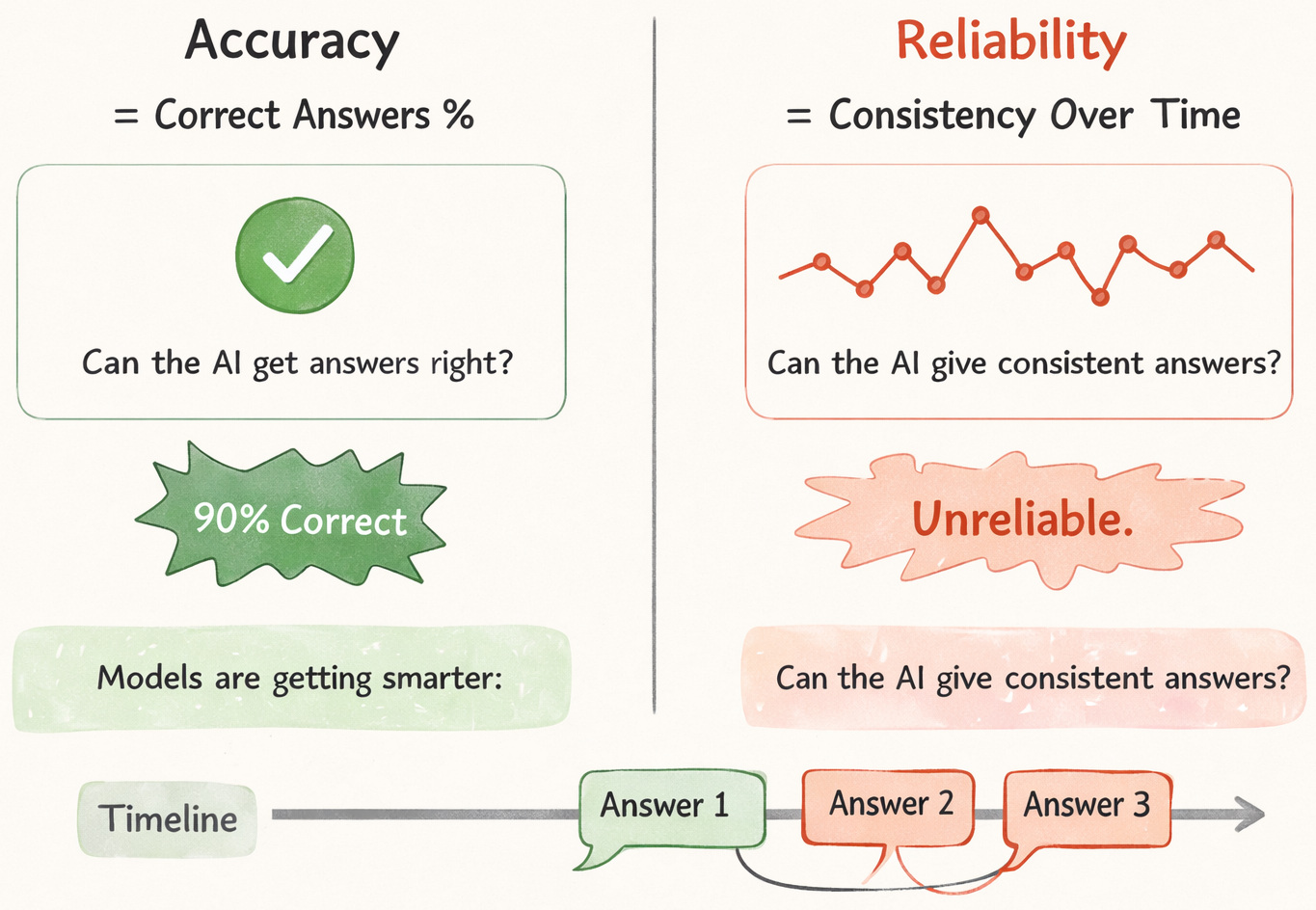
If someone comments on how well an AI tool works, it usually means they are noticing its accuracy.
It is usually enough to verify if the output is correct. Easy to track. Run some searches, calculate a percentage, and you’re done.
Understanding reliability is not so straightforward.
Reliability defines whether the system behaves the same way tomorrow. Why so far? The comparison can be checked even five seconds later. Minor changes in input lead to different outputs. This can be minor (barely perceptible) or glaringly obvious.
Such issues lead to failures.
Accuracy is measured using metrics like precision or F1 score on a fixed dataset. Reliability, on the other hand, is about output stability across repeated runs and changing inputs.
It is often overlooked that a model can have high accuracy but also high variance, making it unreliable in practice.
I’ve seen models with excellent benchmark scores behave unpredictably in production. Different outputs for the same inputs. Completely new response for even small changes in input. These variations are often dismissed as acceptable randomness, even when they impact critical workflows.
For example, a support AI might show 94% accuracy in classifying tickets. But in production, a slightly reworded query could be classified differently. This sensitivity to input perturbations can break downstream systems like routing or automation.
Yes, in theory, LLMs are indeed probabilistic. But this won’t fly with real-life users.
Benchmarks? Users ignore those. What matters instead is belief – can they rely on the display right in front of them?
Read: Ralph Loop Explained: A Smarter Agentic Loop for Building and Testing Software
Data Consistency in AI (The Underrated Metric)
Let’s take a small detour.
Data consistency in AI refers to whether all components in a system function on the same, up-to-date version of data at any given time. In distributed AI pipelines, this includes databases, vector stores, APIs, and caches. It is often assumed that these components are synchronized, even when updates propagate at different speeds.
In practice, inconsistencies increase due to asynchronous updates, caching layers, or delayed data propagation. This leads to what is known as inconsistent reads, where different parts of the system access different versions of the same data.
Imagine a RAG system where the document database is updated immediately, but the vector database is refreshed periodically. A query might retrieve embeddings based on outdated content while displaying updated text. This mismatch between data representations can lead to wrong or misleading outputs, even when each component is functioning as expected.
In such cases, the AI is not reasoning over a single source of truth—it is combining multiple, slightly different versions of it.
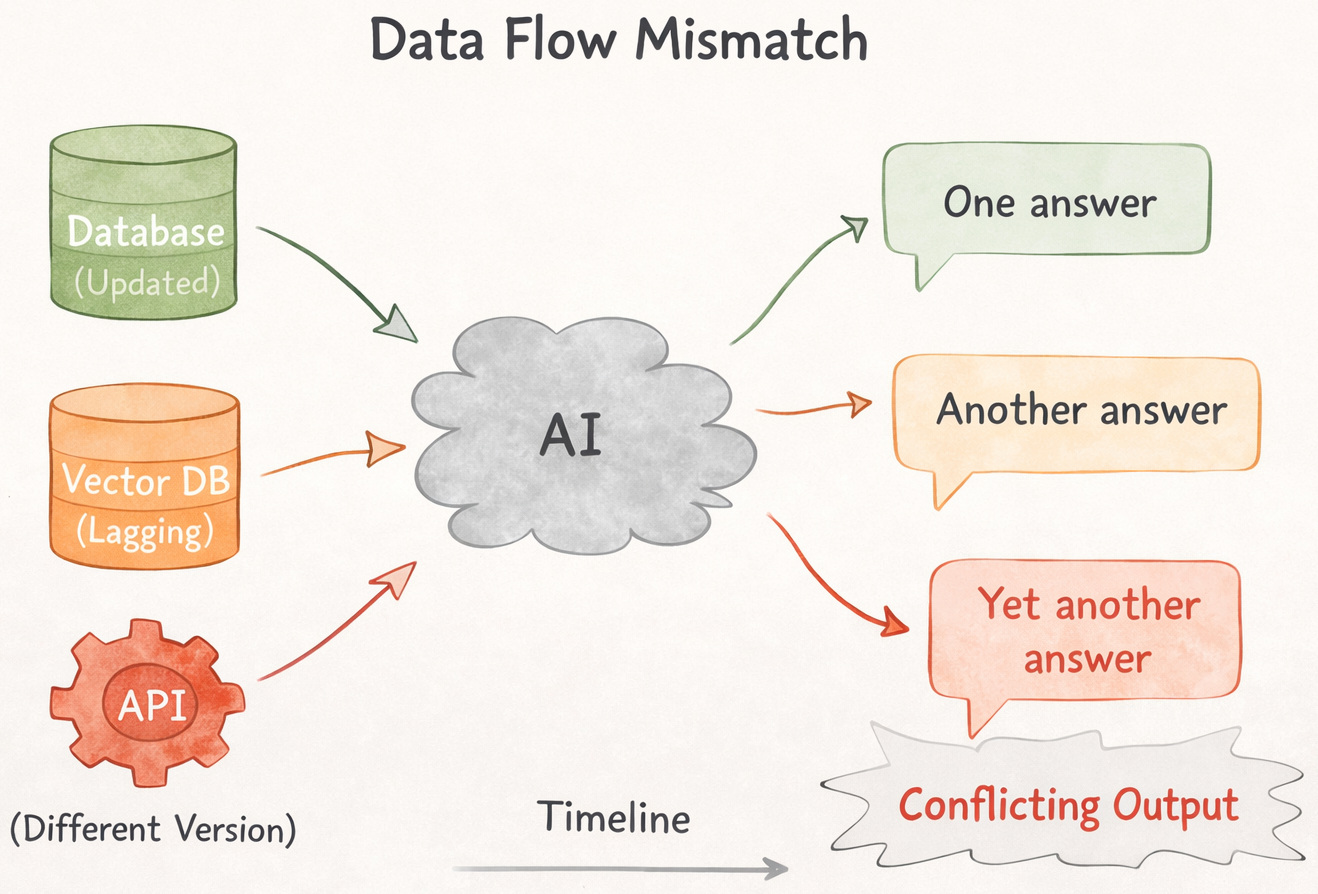
Or a system where the embeddings were updated, yet the metadata stayed behind. Retrieval seemed spot-on, just that the data didn’t match the actual content inside.
No errors. Nothing crashed.
A wrong answer came out of it. That was all.
That’s the scary part about inconsistency. It doesn’t announce itself.
Strong vs. Eventual Consistency: Sounds Abstract, But it Isn’t
- Strong consistency makes sure that every read returns the most recent write. In formal terms, the system behaves as if there is a single, globally consistent state (often associated with linearizability). It is ensured that once a write is completed, all subsequent reads reflect that update immediately.
- Eventual consistency, on the other hand, makes sure that if no new updates occur, all replicas will eventually converge to the same state. However, during the convergence window, different nodes may return different values. Temporary inconsistencies are allowed to improve availability and scalability.
This trade-off works well for systems such as social media, where slight delays are acceptable. But in AI systems, the impact is different.
AI systems don’t just display data; they analyze it. If different components read different versions of the same data, the model may combine conflicting inputs into a single response.
- One component retrieves document version X
- Another retrieves version Y
And the model produces an answer based on both.
Eventual consistency is often chosen for scalability, but its impact on reasoning systems is underestimated.
The Complication of Distributed Systems for AI
Far from being mere algorithms today, AI has grown beyond being models.
Modern AI systems are distributed pipelines built of multiple interconnected components. These usually include data ingestion, preprocessing layers, embedding generation, vector databases, retrieval systems, and LLM inference, often mixed with caching and orchestration layers.
In system design terms, this brings in a distributed state, where different components may hold different versions of data at the same time. It is often assumed that all components work in a consistent state, even though they are updated independently.
- Consistency (all nodes see the same data)
- Availability (every request receives a response)
- Partition tolerance (system continues despite network failures)
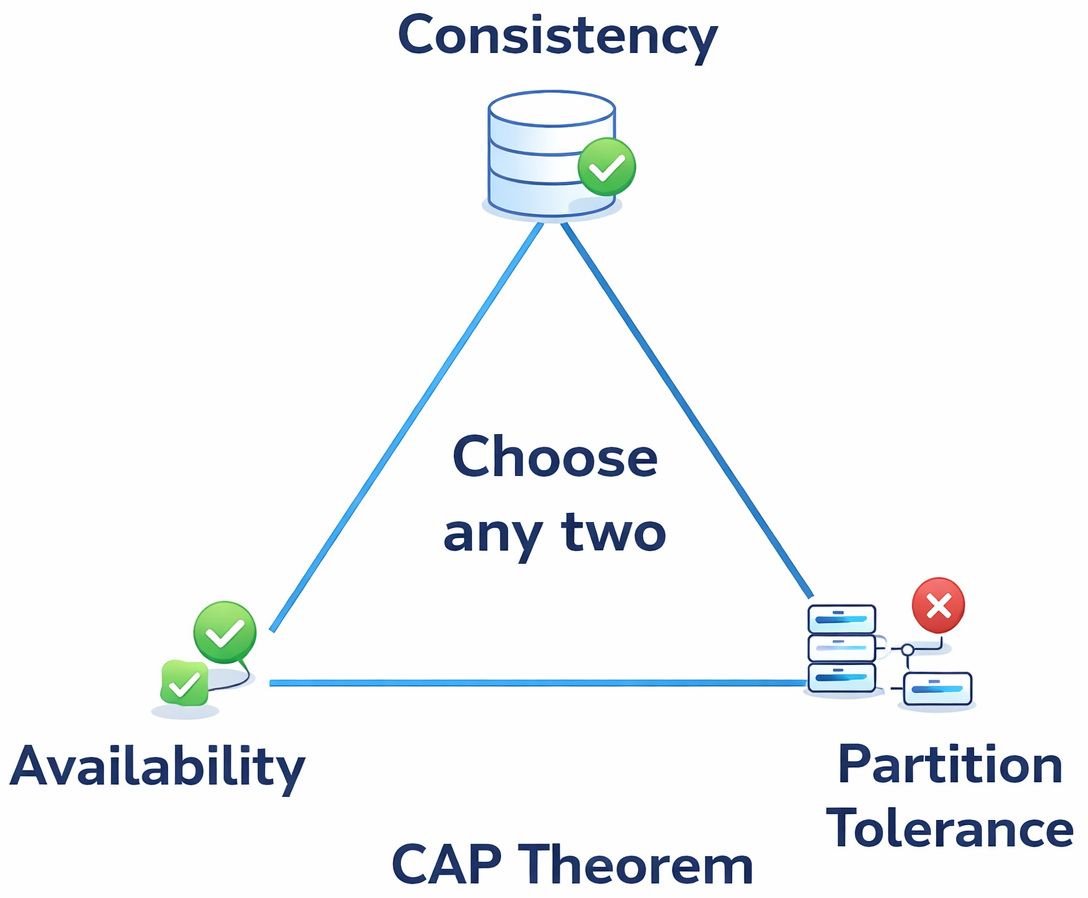
In practice, most AI systems prioritize availability and partition tolerance. This means consistency is relaxed, often resulting in stale reads, cache divergence, or delayed synchronization across components.
For example, a retrieval system may query a vector database replica that has not yet received the latest embedding updates, while another component accesses a more recent version. This leads to non-deterministic behavior, where identical queries can produce different results depending on which node or cache is accessed.
What looks like a reasonable trade-off at the infrastructure level can surface as unpredictability at the application level—and that’s where users begin to lose trust.
LLM Hallucinations and Data Reconsidered
Let’s tackle hallucinations first.
In technical terms, hallucinations in LLMs refer to outputs that are fluent but not grounded in factual or retrieved data. They usually occur when the model generates responses based on its internal probability distribution rather than verifiable context. It is often assumed that hallucinations are purely model-driven, even when they are triggered by upstream data issues.
In retrieval-augmented systems, hallucinations are frequently caused by inconsistent or incomplete context rather than a lack of model capability.
- Non-deterministic ranking
- Embedding drift
- Index updates are not being synchronized
The LLM then generates responses conditioned on whatever context it receives.
Same model. Same prompt.
Different retrieved context → different output.
This behavior is a direct consequence of conditional generation, where the model’s output distribution is highly sensitive to input context.
In such cases, the model is not “inventing” information randomly. It is reasoning over inconsistent evidence.
So the issue isn’t always hallucination in the traditional sense; it’s instability in the data pipeline feeding the model.
Read: Why RAG is the Backbone of Modern Enterprise AI Systems.
RAG Consistency: Where Good Ideas Get Fragile
Retrieval-Augmented Generation (RAG) enhances factual accuracy by grounding LLM outputs in external data. Instead of depending only on the model’s internal knowledge, it retrieves relevant documents and conditions the response in that context.
However, this introduces a new dependency: the reliability of the retrieval pipeline.
- embedding generation (converting text into vectors)
- indexing (storing vectors in a vector database)
- retrieval (similarity search)
- ranking (selecting top-k results)
It is often considered that this pipeline is deterministic, even though multiple stages bring in variability.
- embedding drift (when models or data change over time)
- partial index updates
- non-deterministic ranking or tie-breaking
- asynchronous synchronization between the document store and the vector database
For example, if a document is updated but its embedding is not updated, the retrieval step may return results based on old semantics. Similarly, two retrieval calls may return slightly different top-k results due to ranking instability.
The LLM then generates responses built on this context.
Even small differences in retrieved documents can lead to highly different outputs. This sensitivity arises because LLMs perform conditional generation, where the output distribution depends heavily on the input context.
So while RAG reduces hallucinations, it also introduces consistency challenges in the retrieval layer, and that’s where systems often become fragile.
Syncing Vector Databases with Atomic Changes in AI
In AI systems, the same data is available in multiple forms: documents, embeddings, and metadata. For reliable behavior, these must stay consistent.
Atomic updates mean all related components are updated together, or not at all. It is often accepted that these updates happen synchronously, even when they are handled by separate pipelines.
In practice, updates are often asynchronous, leading to partial state updates.
Say, a document is updated, but its embedding is not. Retrieval still uses the obsolete embedding, while the system shows the new content. This creates a semantic mismatch, where outputs no longer reflect the actual data.
These inconsistencies are hard to detect because each component appears correct in isolation.
This is why atomicity is important for maintaining reliability.
Deterministic AI Outputs: Can We Get There?
People often ask: Can we make AI deterministic?
A system is deterministic if the same input always produces the same output. In traditional software, this is expected. In LLM-based systems, it is not.
LLMs are naturally probabilistic models; they generate outputs by sampling from a probability distribution over possible tokens. This means that even with the same input, outputs can vary depending on factors like sampling parameters (e.g., temperature, top-k).
It is often assumed that fixing the prompt ensures consistent outputs, but generation randomness still plays a role.
That said, variability can be reduced.
- Lowering the temperature or using greedy decoding
- Stabilizing retrieval in RAG pipelines
- Ensuring consistent input data and formatting
Consider that if the same query retrieves slightly different documents across runs, the LLM will generate different responses, even with identical prompts. Controlling retrieval consistency often has a bigger impact than refining model parameters.
Determinism in AI systems is therefore not achieved at the model level, but calculated through control over inputs and system design.
Data Freshness vs Accuracy: A Trade-off That Sneaks In
Data freshness refers to how up-to-date the data is, while accuracy refers to how correct and complete it is. In AI systems, these often conflict.
Real-time pipelines prioritize freshness but can introduce incomplete or inconsistent states due to asynchronous updates. It is often assumed that fresher data is more reliable, even when it has not fully propagated across the system.
Imagine a document may be updated in the database, while its embedding or index lags behind. The system then operates on mixed data versions, leading to inconsistent outputs.
These temporary inconsistencies reduce reliability, even though the data is more recent.
In practice, slightly stale but consistent data often produces more reliable results than fresh but partially updated data.
The Problem of Stale Data in LLMs
Stale data refers to information that is outdated relative to the current system state. In LLM applications, this comes from both the model’s training cutoff and the retrieval layer.
While RAG is used to fetch fresh data, it can still return outdated results if embeddings or indexes are not updated. It is often assumed that retrieval guarantees freshness, even when the underlying data is stale.
Taking the older example, if a document is updated, but its embedding is not. The system continues retrieving old content, leading to incorrect answers.
Outputs remain fluent and confident, but wrong. Stale data issues are often detected only after users notice errors.
Linearizability in AI Pipelines: The Goal We Aim For
Linearizability is a consistency model where all operations appear to occur in a single, globally ordered sequence. Each read reflects the most recently completed write, as if the system had a single source of truth.
- Updates are immediately visible everywhere
- Every component sees the same state
It is often assumed that such consistency exists, even when updates are distributed across independent systems.
In practice, achieving full linearizability is difficult due to distributed architectures and asynchronous updates. However, moving closer to it reduces inconsistent reads and improves overall reliability.
Final Thoughts
Facing a decision like this comes with building AI systems these days.
- A better model?
- Or a more consistent model?
This is the reality.
A typical project hits a wall here when consistency is assumed instead of enforced.
If trust slips away, rebuilding it takes real effort.
Reliability grows step by step, shaped by careful planning behind the scenes. Each decision adds weight only if consistency holds firm.
This is the thing I have learned: Accuracy makes demos look good. Consistency makes systems usable. And reliability? That’s what keeps them alive.
Frequently Asked Questions (FAQs)
- How does RAG consistency affect reliability?
A: RAG improves accuracy, but it introduces new failure points.If your retrieval system isn’t stable- say, embeddings, indexing, or ranking are slightly off- you’ll get inconsistent context. And that leads to inconsistent answers.
- Strong vs eventual consistency: which one should I use for AI systems?
A: It depends, but for critical AI workflows, strong consistency is usually safer.Eventual consistency sounds fine (and it scales well), but in AI systems, small delays can create conflicting inputs. And the model will happily build on that confusion.
- Why does data consistency in AI matter so much?
A: Because the model only works with what it’s given. If your data is inconsistent, your outputs will be too.
|
|